

Method for inserting and extracting hidden information based on English PDF document
A technology of hidden information and extraction methods, applied in the field of hidden information embedding and extraction based on English PDF documents, can solve the problems of difficult extraction of hidden information, damage to daily reading operations and saving operations, and achieve good visual concealment and robust editing behavior. great effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

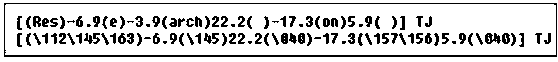
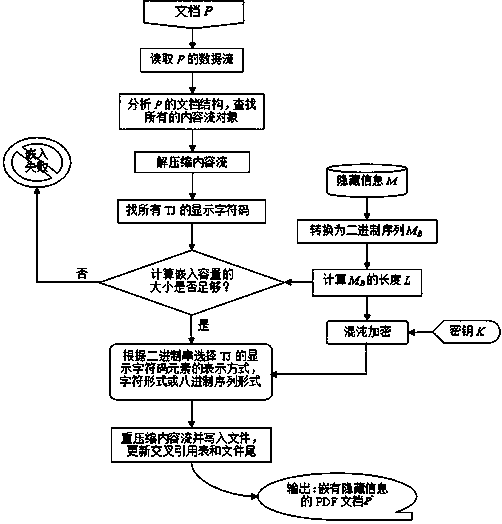
Examples
Embodiment 1
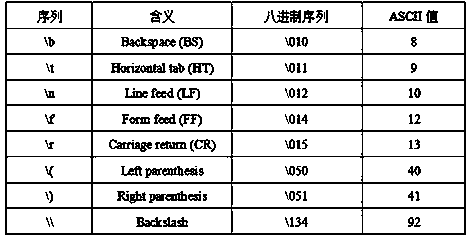
[0051] The method of the present invention embeds information based on the equivalence relationship between characters in the text string and octal sequences. Such as figure 1 As shown in , it is an example of two expressions for displaying character codes. This figure shows the equivalence relationship between characters and octal sequences. In the first line of the figure, the display character code in the operand of operator TJ is expressed in the form of character C; in the second line, the display in the operand of operator TJ Character codes are expressed in the form of the octal sequence \ddd. The content of both descriptions is "Research on". Such as figure 2 Shown is a transfer sequence diagram that partially displays character codes. join figure 2 , the "\" in the operand of the operator TJ is an escape character, adding a backslash before the character has a strict meaning of interpretation, the first column in the table is the character code sequence, and th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More