Web page content extracting method and device
A web page text extraction and web page technology, which is applied in the field of word crawling, can solve the problems of large differences in web page structure, template failure, and inability to guarantee the timeliness of template rule updates, and achieve high accuracy, text integrity, and high text integrity. degree of effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] The drawings constituting a part of the present application are used to provide a further understanding of the present invention, and the exemplary embodiments and descriptions of the present invention are used to explain the present invention, and do not constitute an improper limitation of the present invention.
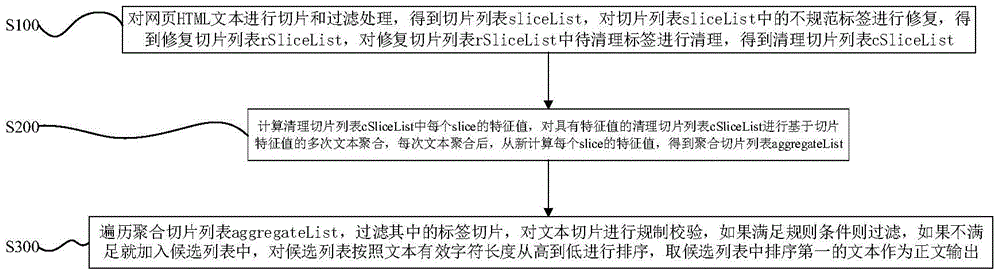
[0034] In this article, the text slice slice is to cut the HTML text of the webpage into three types of text slices: start tag (BTag), text (Text), and end tag (ETag). Since this method is automatic text extraction, it has natural advantages over manual template extraction.
[0035] In order to avoid the inefficiency caused by DOM tree analysis, while maintaining the freedom of operation, see figure 1 One aspect of the present invention provides a method for extracting webpage text, including the following steps:
[0036] Step S100: Slice and filter the HTML text of the web page to obtain a text slice list sliceList, repair irregular tags in the text slice list...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More