

Single-channel sound separation method based on human voice model
A separation method and single-channel technology, applied in voice analysis, instruments, etc., can solve the problems that cannot meet the performance of the human ear system, and achieve the effect of strong practicability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


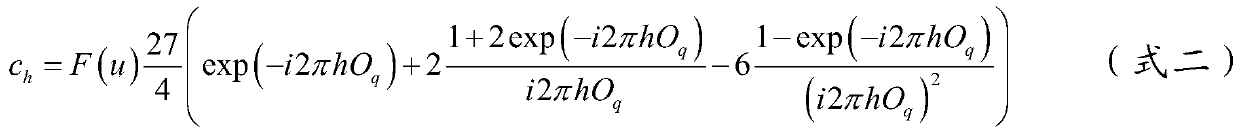

Examples
Embodiment Construction
[0056] The present invention will be further described below in conjunction with specific examples.
[0057] The invention provides a single-channel sound separation method based on the human voice model, which can separate the human voice under extremely noisy conditions, and the quality of the separated human voice signal is high. This single-channel sound separation method can be used for speech enhancement, such as teleconferencing, human-computer interaction scenarios, and can also realize vocal extraction, such as extracting vocals and accompaniment bands from MP3 music signals, and the accompaniment can be used for KTV Singing, the human voice can be used to score the user's singing level. The single-channel sound separation method of the invention has wide application range and strong practicability. The vocal model-based single-channel sound separation method of the present invention will be described below.
[0058] The invention provides a single-channel sound separ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More