

Voice recognition method, device and system and terminal
A speech recognition and speech technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problems of low recognition accuracy and achieve high recognition accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

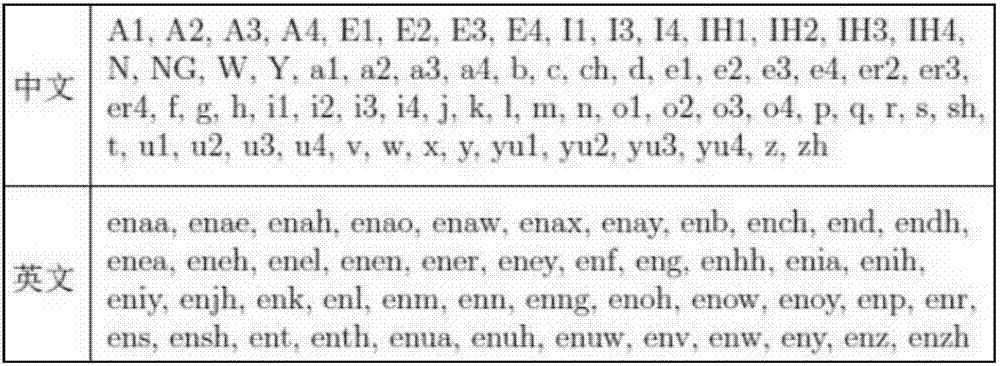
Examples
Embodiment 1
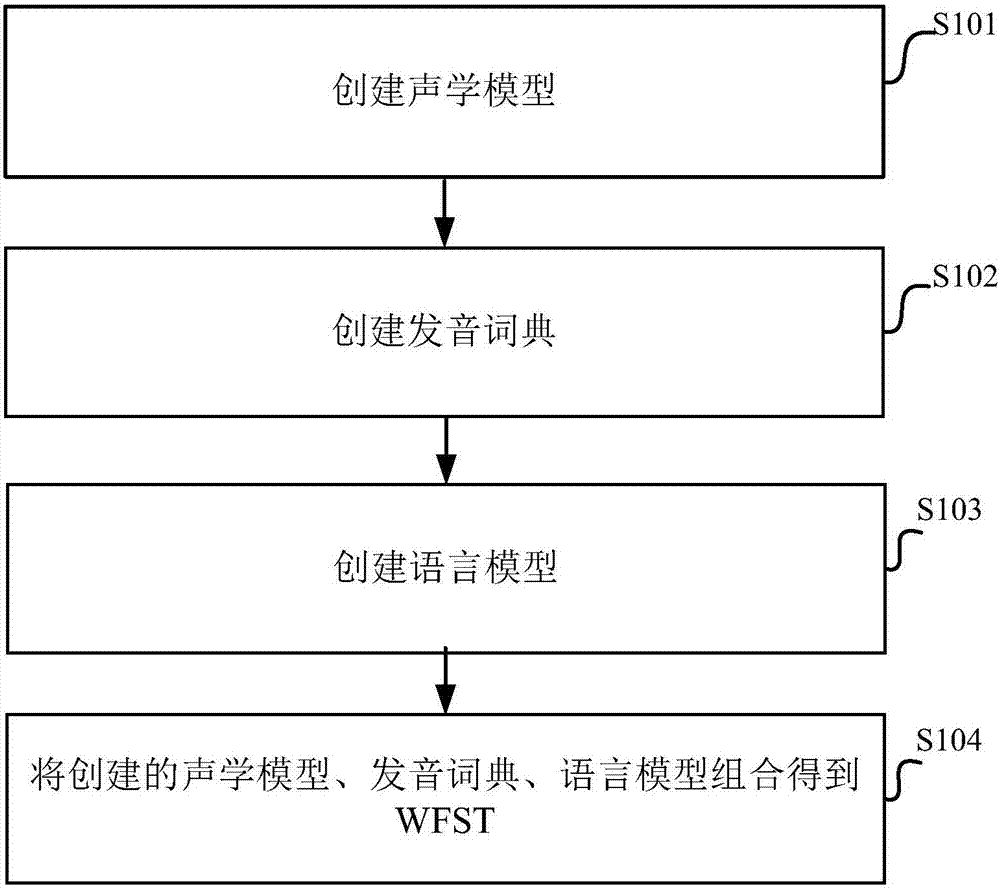
[0030] In Embodiment 1 of the present application, the whole process of creating WFST (WeightedFinite-State Transducers, weighted finite state transducers) according to the embodiment of the present application will be described.
[0031] like figure 1 As shown, creating a WFST according to the embodiment of this application includes the following steps:
[0032] S101, creating an acoustic model.
[0033] The acoustic model is one of the important components of the speech recognition model, which can be used to describe the correspondence between speech features and phoneme states, and is generally modeled and represented by a statistical model. The language model is one of the important components of the speech recognition model, which can be used to describe the probabilistic connection relationship between words.
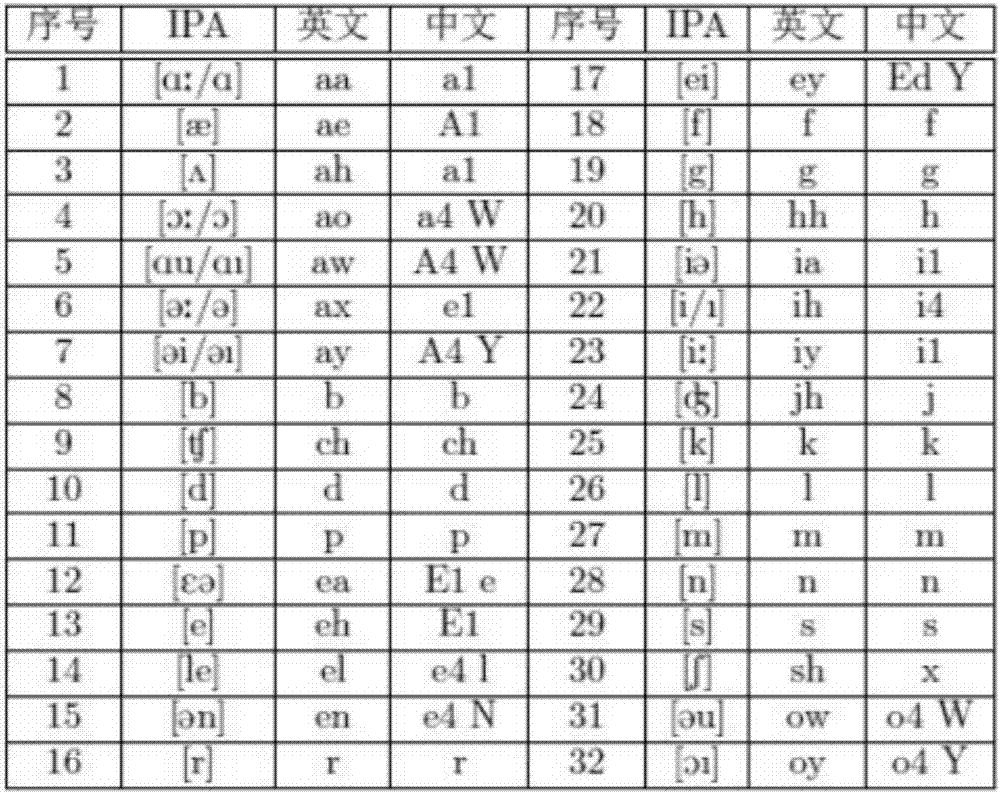
[0034] During specific implementation, the acoustic model can be created in the following manner: determine each phoneme of the first language and the second l...
Embodiment 2
[0093] Figure 5 shows the flow of the speech recognition method according to Embodiment 2 of the present application. like Figure 5 As shown, the speech recognition method according to Embodiment 2 of the present application includes the following steps:
[0094] S501. Receive speech to be recognized.
[0095] During specific implementation, before step S501, a step of prompting the user to input voice may also be included. Specifically, a voice input sign can be displayed to prompt the user to input a voice. The voice input sign can be, for example, a microphone icon, a sound wave icon, etc., or it can be, for example, "Please input voice", "Please speak loudly your favorite baby." " etc., this application does not limit.
[0096] Specifically, the voice input logo can be displayed at a specific position of the input box, such as the front, back, middle, and bottom of the input box, or at a specific position of the input screen, such as in the middle of the screen, etc....
Embodiment 3
[0124] Figure 7 A schematic structural diagram of a speech recognition device according to Embodiment 3 of the present application is shown. like Figure 7 As shown, the speech recognition device 700 shown in Embodiment 3 of the present application includes: a receiving module 701 for receiving speech to be recognized; a feature extraction module 702 for performing feature extraction on the speech to be recognized to obtain feature information; Module 703, used to input the feature information into the weighted finite state converter WFST for recognition, wherein the WFST is obtained by combining the pre-created acoustic model, pronunciation dictionary, and language model, and each phoneme of the first language in the acoustic model There is a corresponding relationship with the second language phoneme, and each first language word in the pronunciation dictionary is phonetically annotated by the second language phoneme.
[0125] In a specific implementation, the speech reco...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More