

Acoustic model training method and device, voice recognition method and device and electronic equipment
An acoustic model and training method technology, applied in speech recognition, speech analysis, instruments, etc., can solve the problem of low accuracy of bilingual mixed speech recognition, and achieve the effect of reducing complexity and improving accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
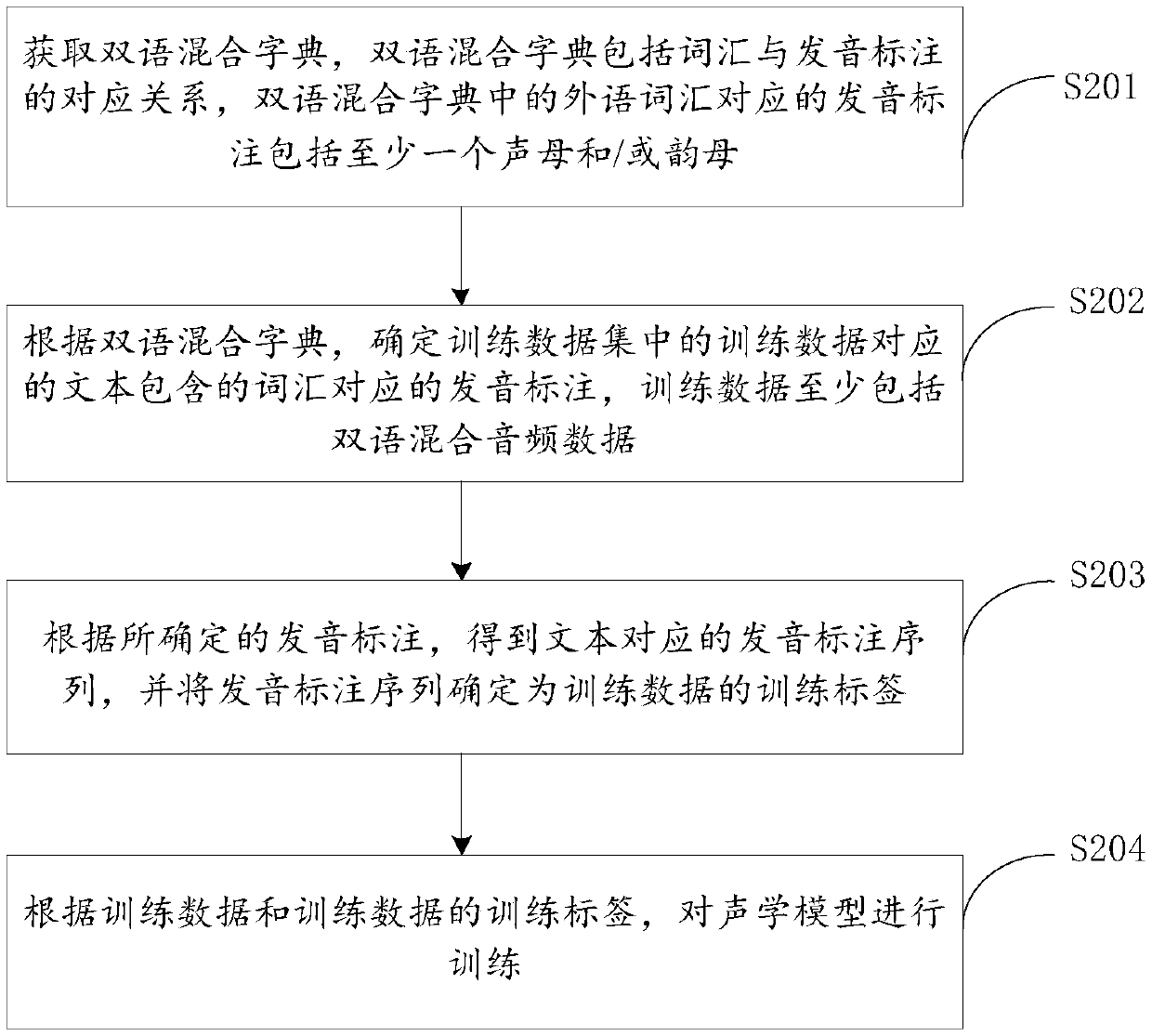
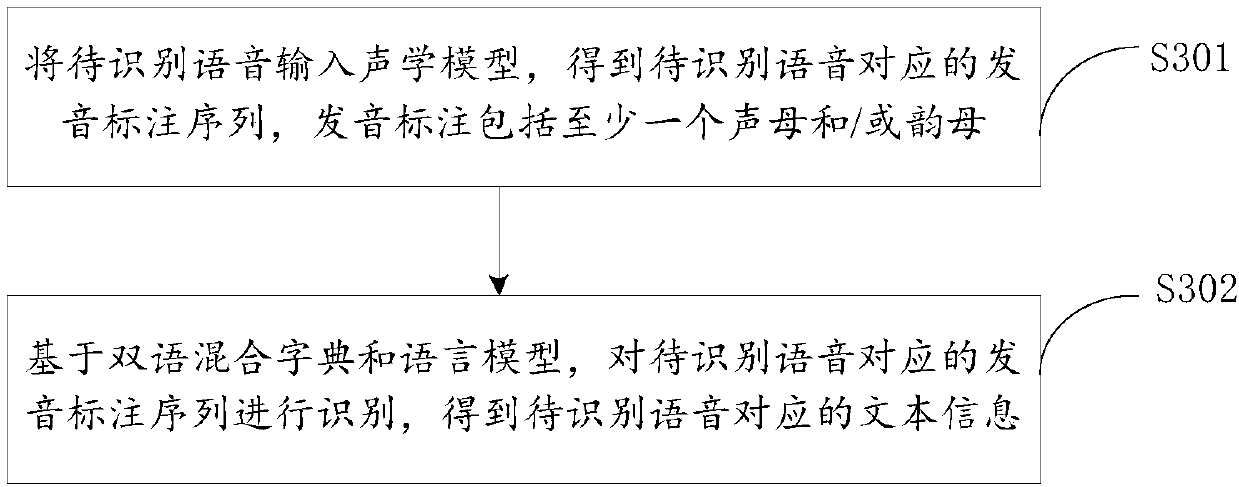
[0030] In order to make the purpose, technical solutions and advantages of the embodiments of the present invention more clear, the technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the drawings in the embodiments of the present invention.
[0031] For the convenience of understanding, the nouns involved in the embodiments of the present invention are explained below:
[0032] A phoneme is the smallest unit of speech. It is analyzed according to the pronunciation actions in a syllable. An action constitutes a phoneme. Phonemes in Chinese are divided into two categories: initials and finals. Initials include: b, p, m, f, d, t, n, l, g, k, h, j, q, x, zh, ch, sh, r, z, c, s. According to the structure, finals can be divided into single finals, compound finals, nasal finals, etc. Among them, single finals are composed of one vowel, such as: a, o, e, ê, i, u, ü; complex finals are composed of two Or...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More