

An Object Storage Based Crawler Network Path Tracing Method
A technology of object storage and network path, which is applied in the field of path tracking research in software engineering, can solve the problem of serious disk IO load, achieve the effect of improving IO efficiency, decoupling, and ensuring retrieval efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
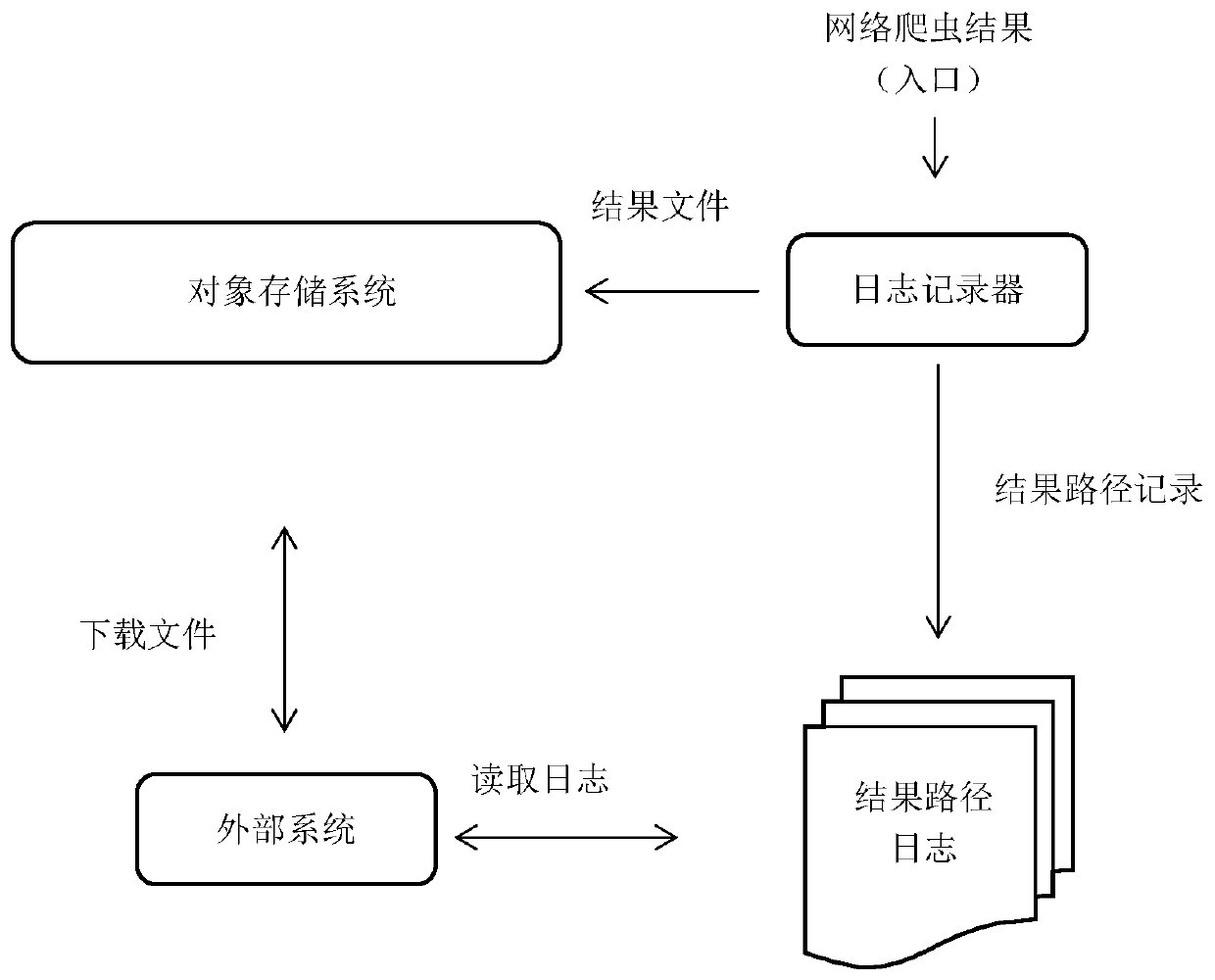
[0022] Such as figure 1 As shown, in this embodiment, a crawler network path tracking method based on object storage includes the following steps:
[0023] 1. Deploy the object storage system and log processor.
[0024] The object storage system is a file storage system based on the HBASE distributed file system, which can support the storage of PT-level files. By calling the HTTP interface and passing corresponding parameters, deletion (DELETE), creation (POST), and rewriting (PUT) of files on the object storage system can be implemented. It should be noted that the object storage system of the present invention can only provide file deletion, creation and rewriting, and does not support incremental writing of files.
[0025] The log processor is a single piece, which is used to process the received results and distinguish them by crawler. Each crawler is correspondingly written into a result path log file, which is convenient for the subsequent system to read and index.
...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More