

Multi-modal dialogue system and method guided by user attention
A dialogue system and multi-modal technology, applied in character and pattern recognition, biological neural network models, special data processing applications, etc., can solve the problems of limited attention and neglect at the attribute level
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
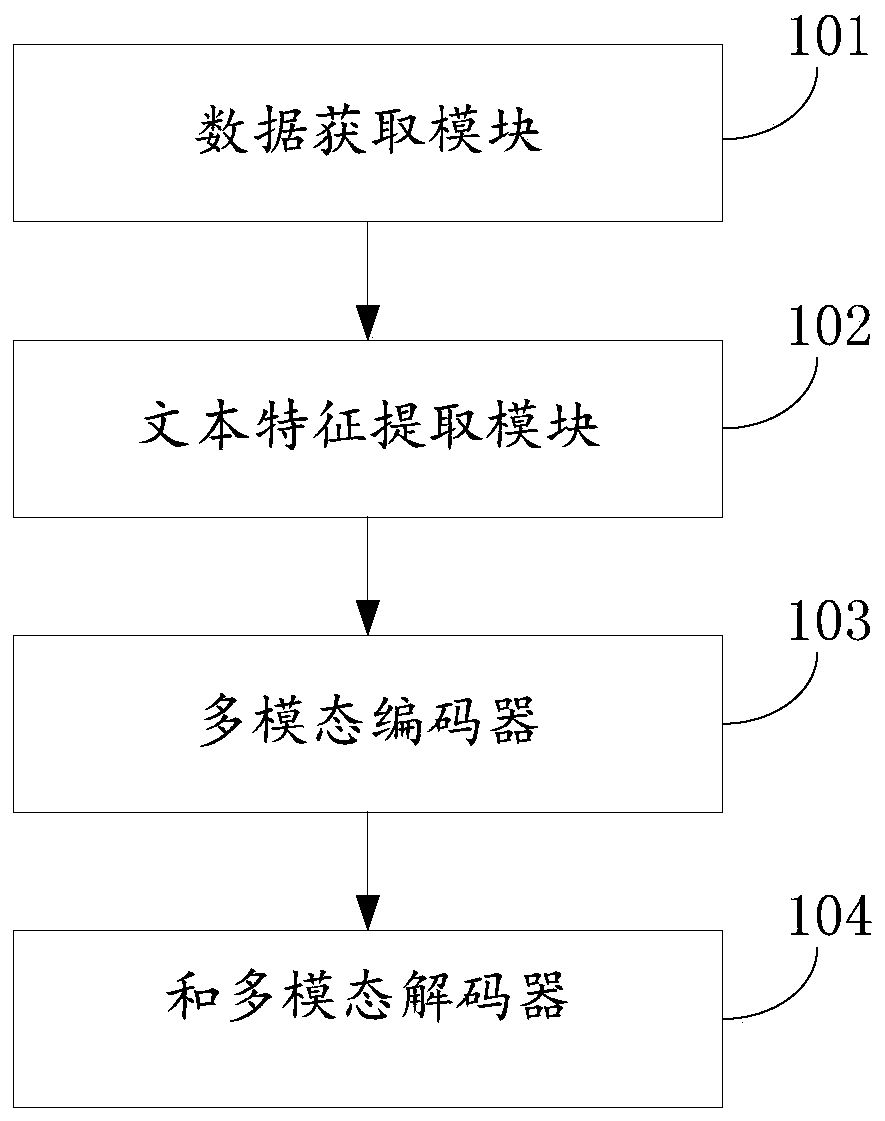
[0055]This embodiment provides a multi-modal dialogue system guided by user attention, please refer to the attached figure 1 , the dialog system includes a data acquisition module 101 , a text feature extraction module 102 , a multimodal encoder 103 and a multimodal decoder 104 .
[0056] Specifically, the data acquisition module 101 is configured to acquire the text information of the interaction between the user and the chat robot, and the visual image information of the product desired by the user.
[0057] The text feature extraction module 102 is used to train text information using a two-way cyclic neural network based on the attention mechanism, and generate attention-weighted text features.
[0058] The multimodal encoder 103 is used to extract the visual features of the visual image by using the convolutional neural network model, and input the visual features into the classification-attribute combination tree for traversal to obtain more representative attribute-leve...
Embodiment 2
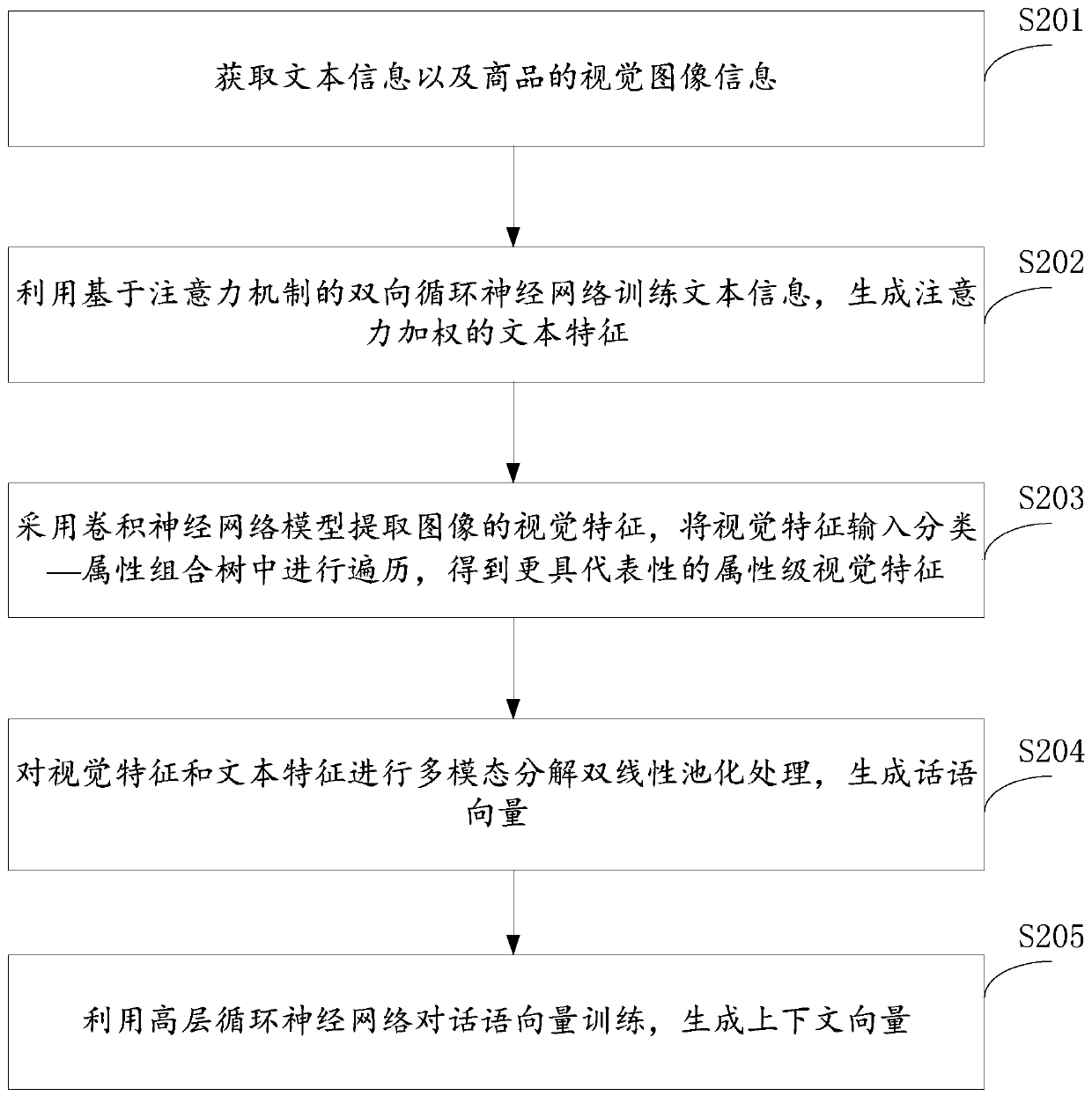
[0074] This embodiment provides a multi-modal dialogue method for user attention guidance. At a high level, the dialogue method uses an attention mechanism-based bidirectional recurrent neural network (RNN) to generate attention-weighted text features. ; at a low level, a multimodal encoder and decoder are employed to encode multimodal utterance vectors and generate multimodal text responses, respectively.
[0075] Please refer to the attached figure 2 , the user attention-guided multimodal dialogue method includes the following steps:
[0076] S201. Acquire text information and visual image information of commodities.
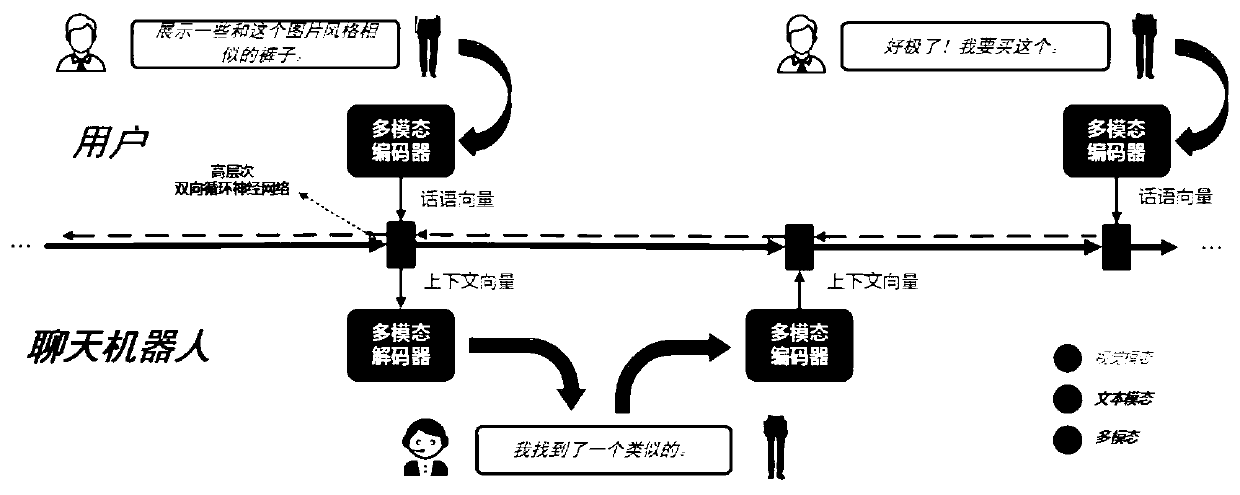
[0077] Specifically, obtain the text information of the interaction between the user and the chat robot, as well as the visual image information of the desired product, such as image 3 shown.
[0078] S202. Using an attention mechanism-based bidirectional recurrent neural network to train text information to generate attention-weighted text features.
[...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More