

Method and system for providing gpu service
A server-end and status description technology, applied in the field of providing GPU services, can solve the problems of multiple memory resources, occupation, and lack of deep learning framework Caffe support, etc., to achieve the effect of meeting service requests and high efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

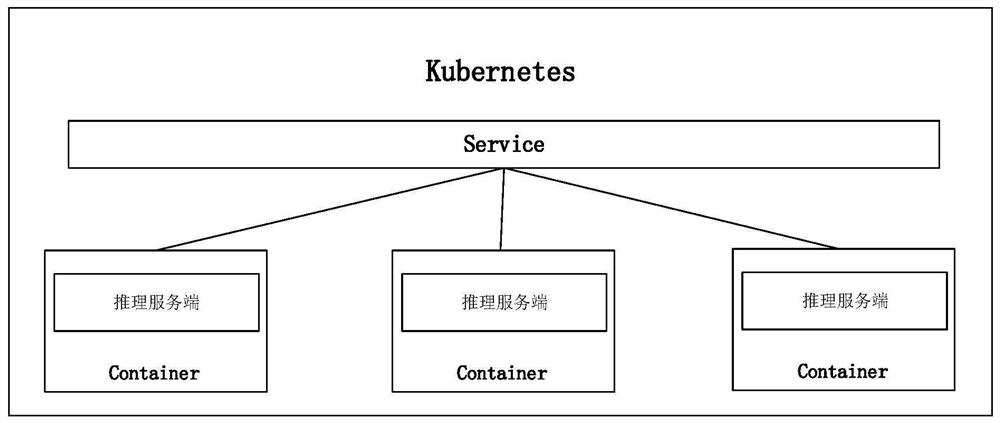
Examples
Embodiment Construction
[0027] The technical means or technical effects involved in the present disclosure will be further described below. Obviously, the provided examples (or implementations) are only some of the implementations that the present disclosure intends to cover, but not all of them. All other embodiments that can be obtained by those skilled in the art based on the embodiments in the present disclosure and the explicit or implied representations of the pictures and texts will fall within the protection scope of the present disclosure.
[0028] In general, this disclosure proposes a method for providing GPU services, including the following steps: start a container in a container cluster management system; read configuration information and load an inference server in the container according to the configuration information; receive a request from a client information, according to the request information, send a calculation instruction to the inference server, and the calculation instruc...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More