Sentence similarity calculation method based on edge information and semantic information
A technology of sentence similarity and semantic information, applied in special data processing applications, unstructured text data retrieval, text database query, etc., can solve the problems of high computational complexity and low accuracy, and achieve the effect of improving computational accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
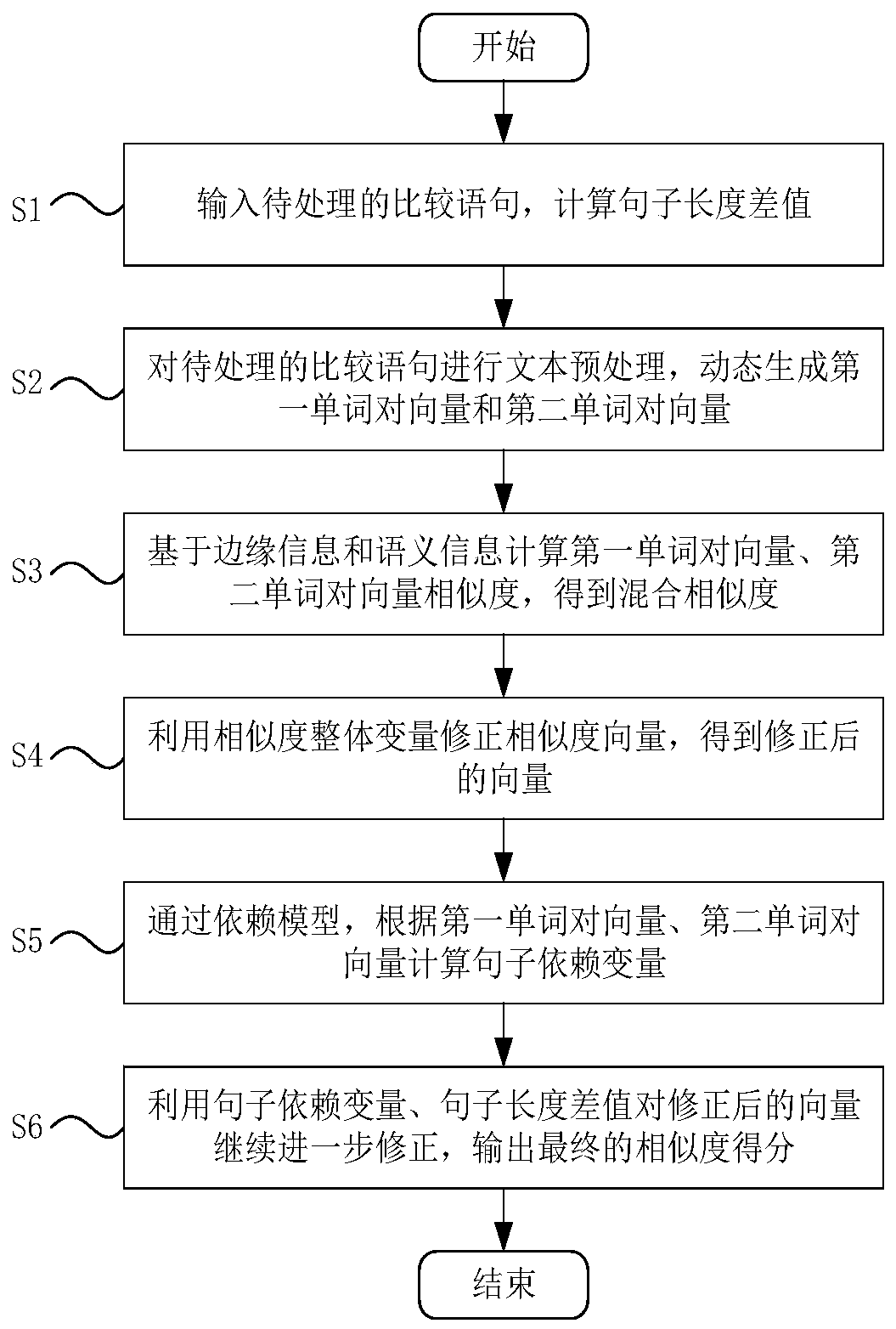
[0069] Such as figure 1 As shown, a method for calculating sentence similarity based on edge information and semantic information includes the following steps:
[0070] S1: Input the comparison sentence to be processed, and calculate the difference in sentence length;
[0071] S2: Perform text preprocessing on the comparison sentence to be processed, and dynamically generate the first word pair vector and the second word pair vector;
[0072] S3: Calculate the similarity of the first word pair vector and the second word pair vector based on the edge information and semantic information to obtain the mixed similarity;
[0073] S4: Use the overall similarity variable to correct the similarity vector to obtain the corrected vector;
[0074] S5: Calculate sentence dependent variables based on the first word pair vector and the second word pair vector through the dependency model;
[0075] S6: Use sentence dependent variables and sentence length differences to further correct the corrected ve...
Embodiment 2
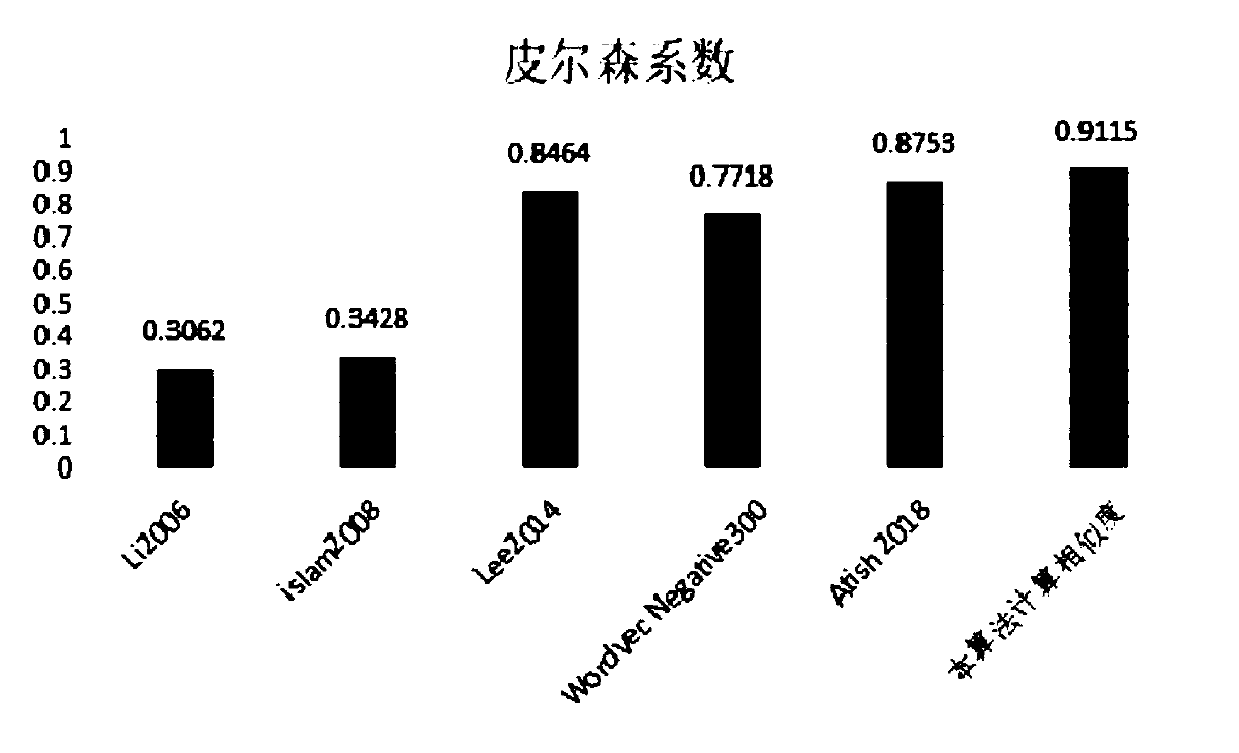
[0106] More specifically, on the basis of Example 1, such as image 3 As shown, the Pearson coefficient of the algorithm proposed by the present invention is higher than the Pearson coefficient of the existing traditional algorithm, and the performance is better than that of the existing traditional algorithm. Table 1 is the R&G word pair similarity data table, specifically:
[0107] Table 1 R&G word pair similarity data table
[0108]
[0109]
[0110]
[0111] The above table is the specific value for calculating the similarity of R&G word pairs using this algorithm.
[0112] More specifically, the step S4 is specifically:
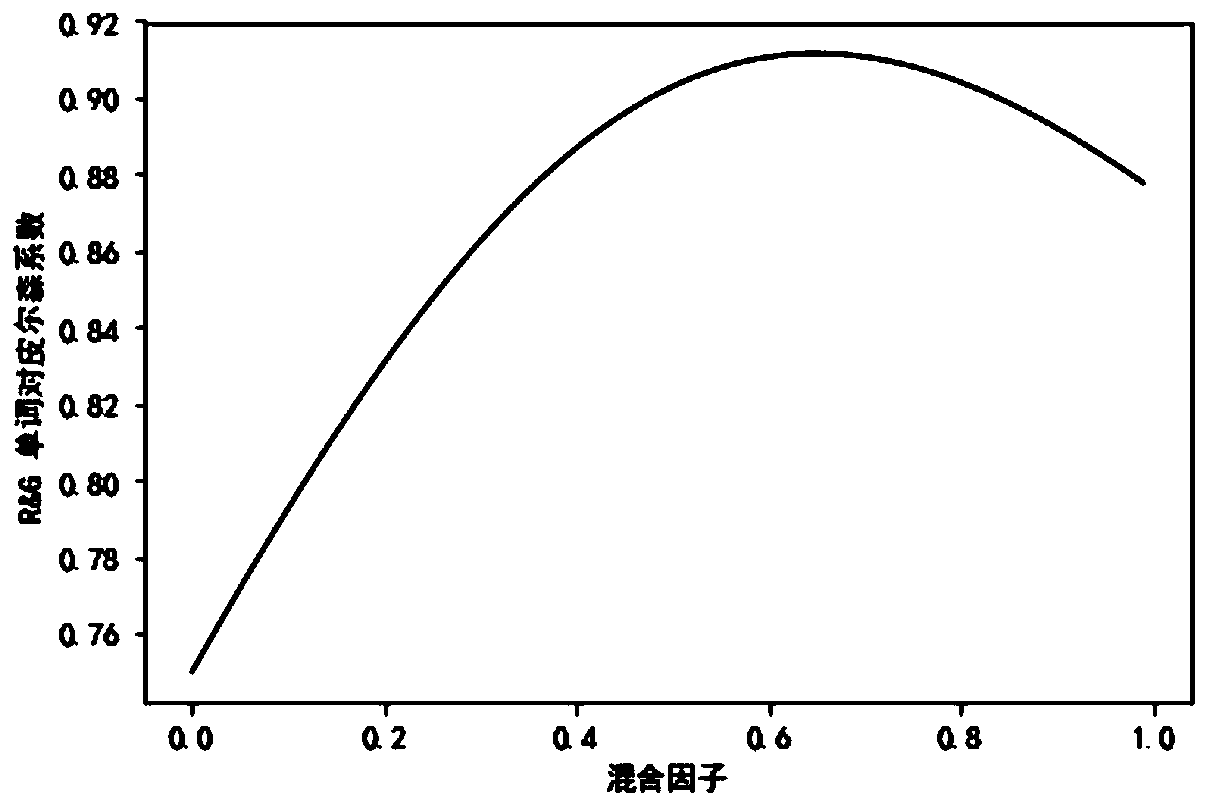
[0113] S41: According to the definition of R&G, when the word similarity value is greater than 0.8025, the word pair can be defined as a synonym [6], so the number of data exceeding 0.8025 value in the two mixed similarity vectors is counted, and the overall similarity variable is calculated, specifically as :
[0114] ω=sum(C1,C2) / γ
[0115] Where C 1 , C 2 Res...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



