

Method and system for realizing video and audio driven face animation combined with modal particle features
A technology that drives the face and realizes the system. It is used in animation production, speech analysis, speech recognition, etc. It can solve the problem of not taking into account the characteristics of the modal particles, and achieve the effect of vivid facial expressions.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
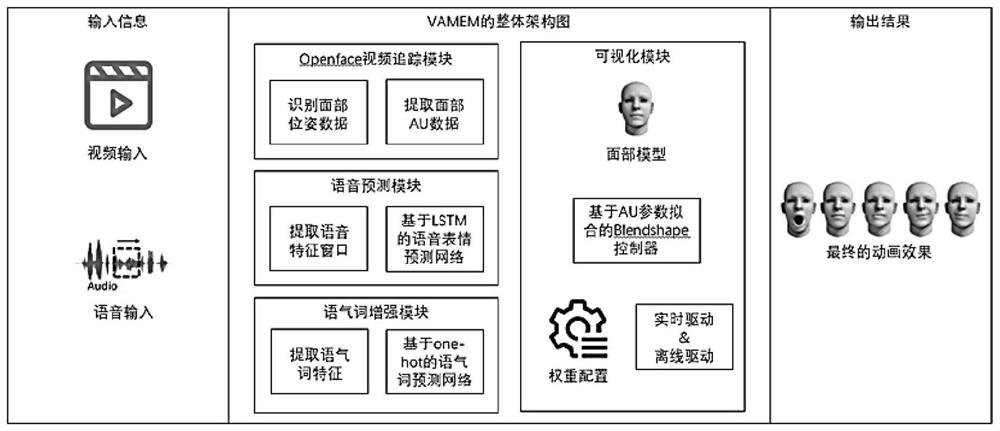
[0022] like figure 1 As shown, the present embodiment relates to a video-audio-driven facial animation implementation system that combines modal particle features, including: an openface video tracking module, a speech prediction module, a modal particle enhancement module and a visualization module, wherein: the openface video tracking module is based on Process video input information, perform facial position and pose calculations to obtain facial rotation angles and line-of-sight rotation angles, and perform expression AU parameter detection to obtain AU intensity parameters. The voice prediction module uses the extracted audio features to construct an audio feature matrix based on the processed voice input information. The memory network (LSTM) is used to predict the mapping relationship between the audio feature window and the facial AU parameters, that is, the expression AU parameters. The modal particle enhancement module converts the speech content into text, and furthe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More