Data augmentation method and device for OCR, apparatus and storage medium
A data and data set technology, applied in the field of character recognition, can solve the problems of high cost and poor targeting of training samples, and achieve the effect of improving pertinence and reducing costs
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
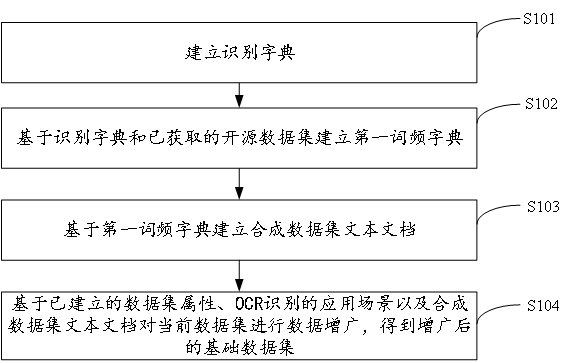
[0047] figure 1 It shows the implementation process of the data augmentation method for OCR recognition provided by Embodiment 1 of the present invention. For the convenience of description, only the parts related to the embodiment of the present invention are shown, and the details are as follows:
[0048] In step S101, a recognition dictionary is established.
[0049] In the embodiment of the present invention, the recognition dictionary may include Chinese characters, English letters, and Chinese and English punctuation marks. The recognition dictionary can be established according to the Chinese character code standard of our country. The Chinese character code standard GB2312-80 of my country stipulates 3755 first-class Chinese characters and 3008 second-class Chinese characters, totaling 6763 Chinese characters. Compared with the first-level Chinese characters, the word frequency of the second-level Chinese characters is relatively low, but they also appear in daily lif...
Embodiment 2
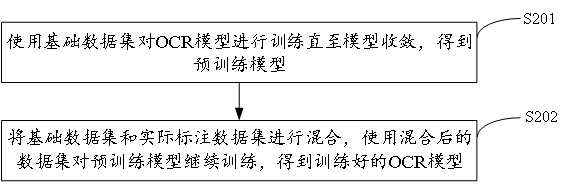
[0079] figure 2 It shows the implementation process of the OCR model training method based on the data augmentation method described in the first embodiment provided by the second embodiment of the present invention. For the convenience of explanation, only the parts related to the embodiment of the present invention are shown, and the details are as follows:
[0080]Considering that in order to achieve a more ideal text recognition effect, it is not enough to rely on basic data sets (open source data sets and synthetic data sets) to train the OCR model, and some actual data sets are needed to fine-tune the model. Therefore, the following steps can be adopted when training the OCR model:
[0081] In step S201, the OCR model is trained using the basic data set described in Embodiment 1 until the model converges to obtain a pre-trained model;
[0082] In the embodiment of the present invention, the OCR model may be a model adopting a common structure such as CRNN. In the spec...
Embodiment 3
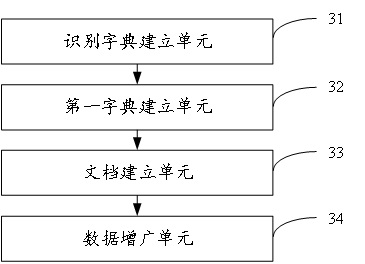
[0088] image 3 The structure of the data augmentation device for OCR recognition provided by Embodiment 3 of the present invention is shown. For the convenience of description, only the parts related to the embodiment of the present invention are shown, including:
[0089] A recognition dictionary building unit 31, configured to build a recognition dictionary;
[0090] The first dictionary establishment unit 32 is used to establish the first word frequency dictionary based on the recognition dictionary and the obtained open source data set;
[0091] A document building unit 33, configured to create a synthetic data set text document based on the first word frequency dictionary; and
[0092] The data augmentation unit 34 is configured to perform data augmentation on the current dataset based on the established attributes of the dataset, the application scenario identified by OCR, and the text document of the synthesized dataset to obtain an augmented basic dataset.
[0093] ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com