

Speech recognition device and speech recognition method
A speech recognition and speech technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as misrecognition, non-verbal sounds cannot get high sound scores, and the value of useless information sound scores increases, and achieve practical value high effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment approach 1
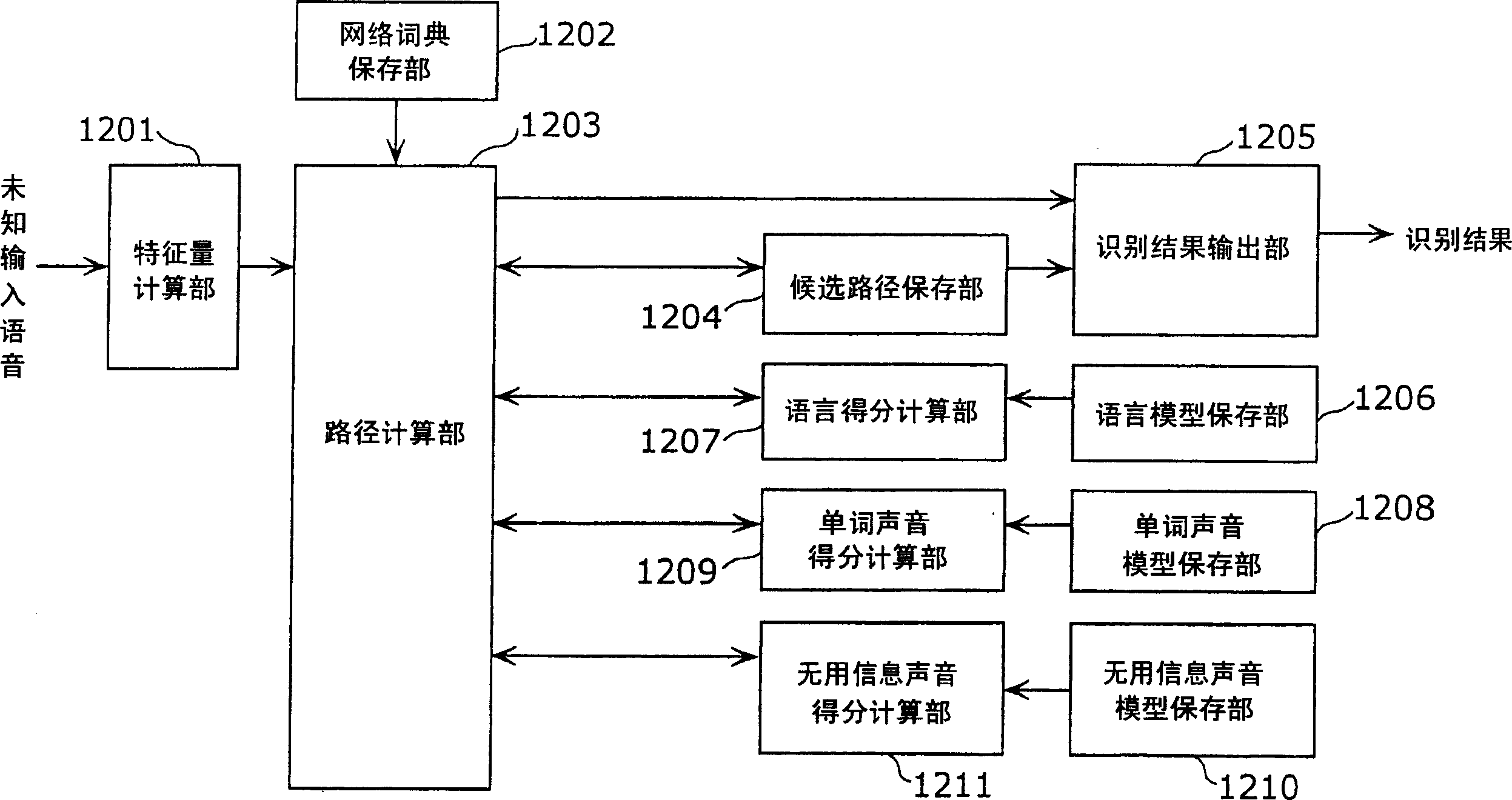
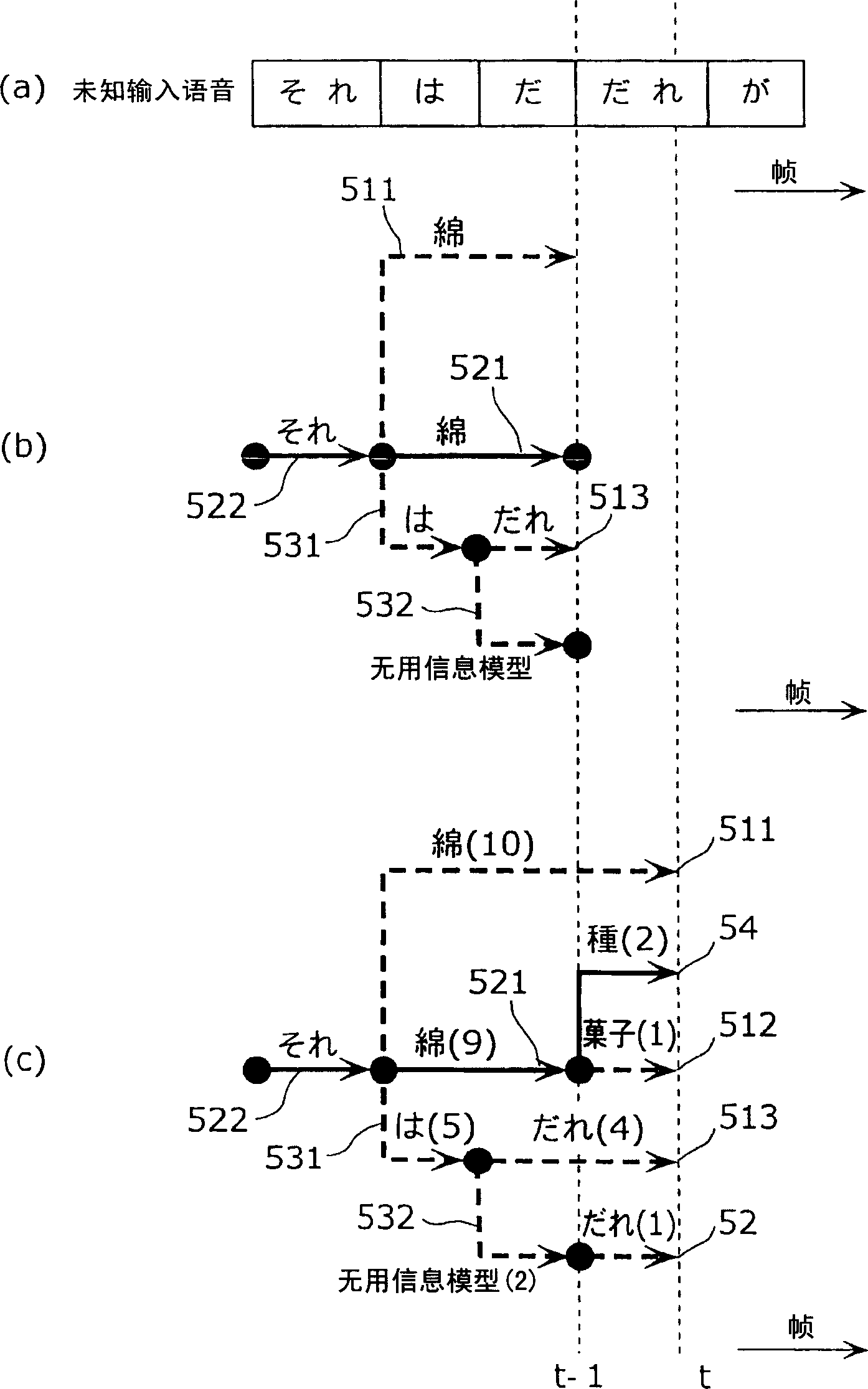
[0074] Fig. 3 is a block diagram showing the functional structure of the speech recognition device according to Embodiment 1 of the present invention. However, in Embodiment 1, a case where the target of non-language estimation is sound eating is described as an example.
[0075]Speech recognition device 1 is the computer device that uses speech recognition to operate television, and as shown in Figure 3, comprises feature amount calculation part 101, network dictionary storage part 102, route calculation part 103, candidate route storage part 104, recognition result output part 105. Language model storage unit 106, language score calculation unit 107, word sound model storage unit 108, word sound score calculation unit 109, unnecessary information sound model storage unit 110, useless information sound score calculation unit 111, non-linguistic sound inference unit 112 , and the unnecessary information sound score correction unit 113 and the like.
[0076] Wherein, each part...
Embodiment approach 2
[0131] Next, a speech recognition device according to Embodiment 2 of the present invention will be described.
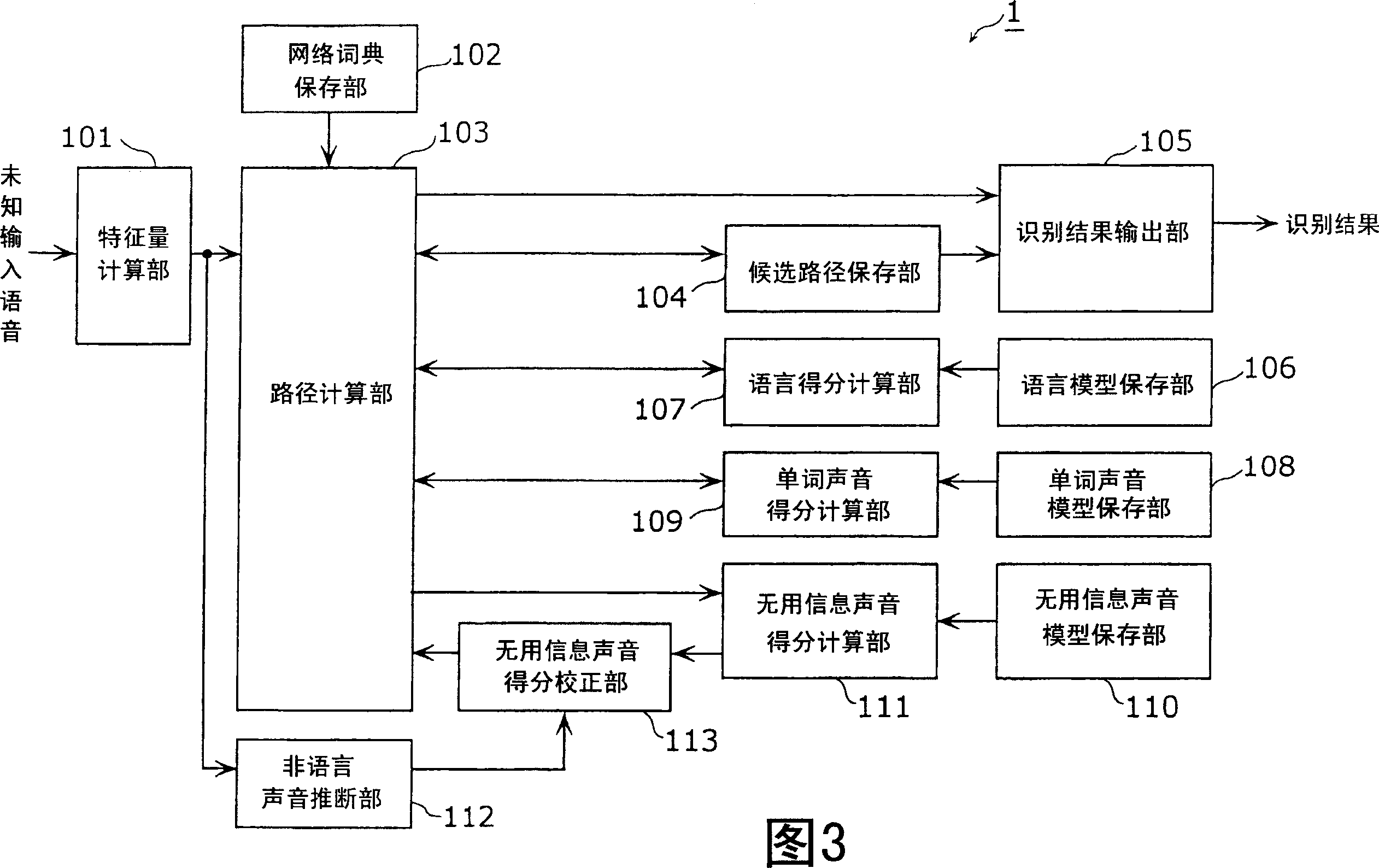
[0132] FIG. 6 is a block diagram showing the functional structure of a speech recognition device according to Embodiment 2 of the present invention. However, in Embodiment 2, the case where the object of non-language estimation is laughter is described as an example. In addition, the parts corresponding to the speech recognition device 1 of Embodiment 1 are assigned the same reference numerals, and detailed description thereof will be omitted.
[0133] Speech recognition device 2 is the same as speech recognition device 1 and operates the computer device of TV set by speech recognition, as shown in Figure 6, except comprising feature amount calculation part 101, network dictionary storage part 102, route calculation part 103, candidate route storage unit 104, recognition result output unit 105, language model storage unit 106, language score calculation unit 107, w...
Embodiment approach 3
[0158] Next, a speech recognition device according to Embodiment 3 of the present invention will be described.
[0159] Fig. 8 is a block diagram of the functional structure of the voice recognition device according to Embodiment 3 of the present invention, Figure 9 It is a schematic diagram of a situation where a user faces a mobile phone with a camera and inputs an email by voice. However, in the third embodiment, a case will be described taking as an example a case where a mobile phone with a camera detects a smile or a cough using a camera image as an input, and corrects a unnecessary sound score for speech recognition. In addition, components corresponding to those of the speech recognition device 1 according to Embodiment 1 are given the same reference numerals, and description thereof will be omitted.
[0160] The voice recognition device 3 is a computer device such as a mobile phone that uses voice recognition to create emails. As shown in FIG. Output unit 105, lang...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More