

Method for automatically classifying text documents by utilizing body
A text document and automatic classification technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as difficult to improve classification accuracy, cumbersome, and no consideration of semantic relationship between words, so as to save training and learning The process of improving accuracy and enriching the effect of concept content
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

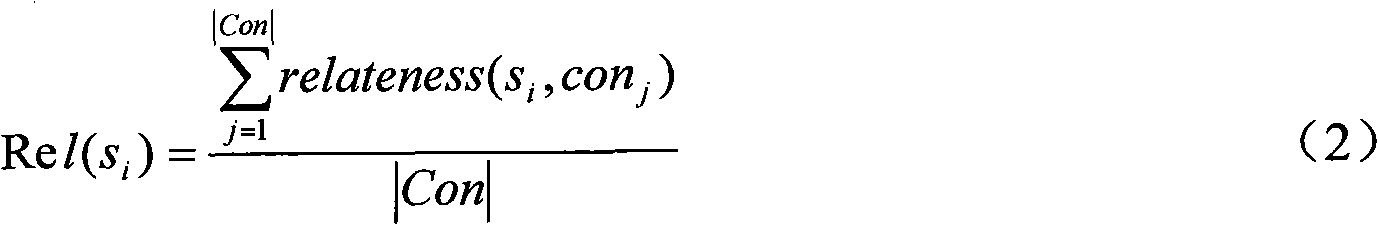
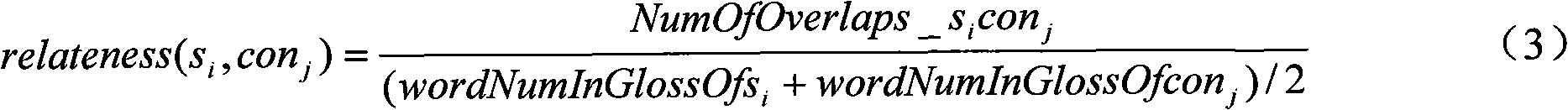
Examples
Embodiment Construction
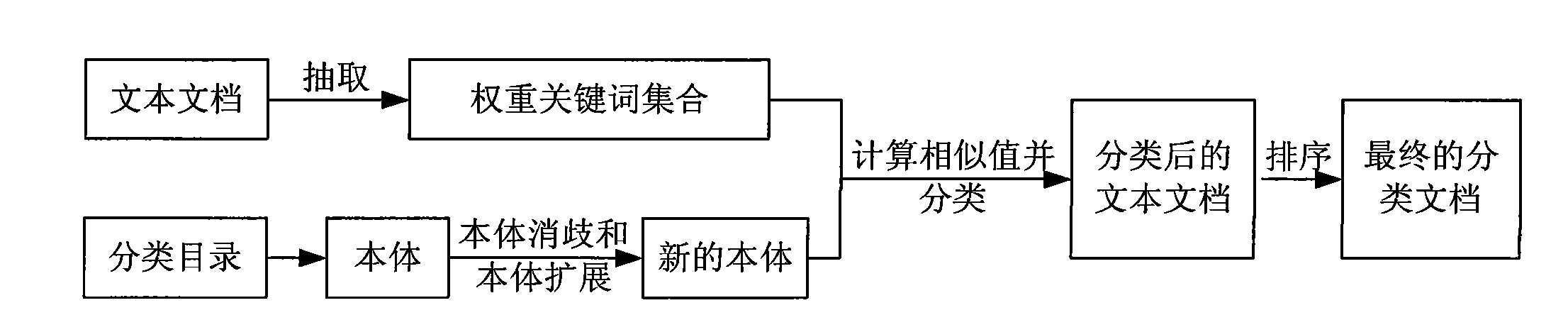
[0038] The present invention will be further described now in conjunction with accompanying drawing:
[0039]According to the method for classifying text documents using ontology proposed by the present invention, we have implemented it using Java and Perl languages, and the specific implementation process is as follows:
[0040] The text document classification method using ontology is divided into the following four steps:
[0041] Step 1: Construction of the keyword set of the text document. Here, the KEA algorithm is used to extract the weighted keyword set of each text document in the text document collection to be classified, specifically: for the text document collection D={d 1 , d 2 ,...,d |D|} (|D| indicates the number of text documents in the text document collection D) in each text document d i , first, using Naive Bayesian estimation, by considering the frequency tf×idf of words (existing words) appearing in text documents, the average position Occurrence of wo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More