

Multi-document subject discovery method based on two-layer clustering
A discovery method and multi-document technology, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve problems such as uneven distribution, inconvenient discovery of multi-document topics, and the impact of sentence clustering, so as to reduce the spatial dimension. , highlight the similarity of the theme content, and improve the effect of computing speed
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


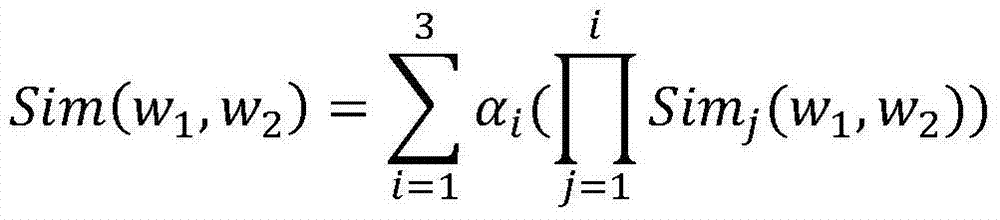
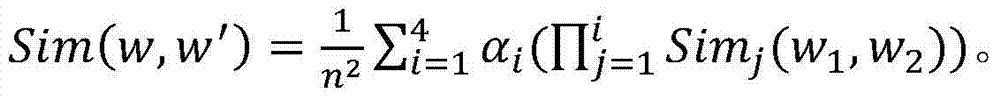
Examples
Embodiment
[0041] Such as figure 1 As shown, the multi-document topic discovery method based on two-level clustering in this embodiment includes the following steps:
[0042] S1. Taking multiple documents as input, preprocessing each document, including segmenting the document, segmenting the sentence, obtaining the noun set and verb set in the multi-document collection, and disambiguating the polysemous words among them Processing; the specific method of word sense disambiguation processing is:
[0043] For the result after word segmentation, first mark its part of speech, focusing only on the noun set and the verb set. For the polysemous word w, first use the semantic dictionary to get its meaning, and then calculate the meaning of each word and the k words of the same part of speech before and after it. The sum of the word meaning similarity of.
[0044] The calculation method of the above-mentioned word meaning similarity is:
[0045] S11. For the word meaning similarity of the Chinese co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More