

A Method of Outlier Data Mining in Large-Scale Datasets Based on Graph Theory
A large-scale data, outlier data technology, applied in character and pattern recognition, instruments, computer parts and other directions, can solve problems such as difficulty in screening outlier data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

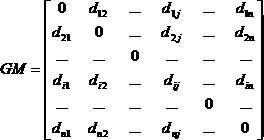
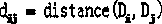
Examples
Embodiment Construction
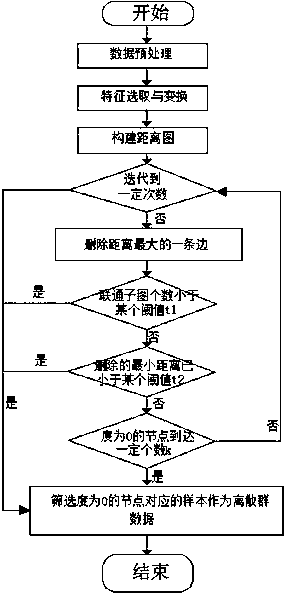
[0037] The present invention will be further described below in conjunction with specific embodiments according to the accompanying drawings of the description:
[0038] A large-scale data set outlier data mining method based on graph theory, the method deletes the edges in the graph, and after multiple iterations, the samples corresponding to the nodes with a degree of 0 in the graph are the outlier data screened by this method .
[0039] The acyclic graph is an undirected graph based on distance, the nodes in the graph are samples in the data set, and the weight of an edge is the distance between samples corresponding to two nodes.
[0040] Such as figure 1 As shown, the method includes the following steps:
[0041] 1) Data preprocessing
[0042] The purpose of this step is to preprocess the data, eliminate the inconsistency between the data and normalize each data, including specific operations such as data cleaning, data integration, data transformation, data reduction,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More