

Density-based text clustering algorithm
A text clustering algorithm and density technology, applied in the field of keyword extraction and semantic analysis, can solve the problems of inaccurate calculation of similarity between documents, high-dimensional sparseness, and impact on clustering accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

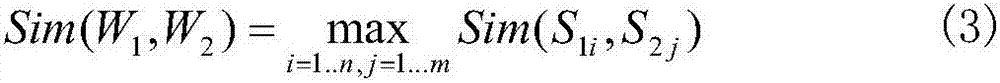
Examples
Embodiment Construction
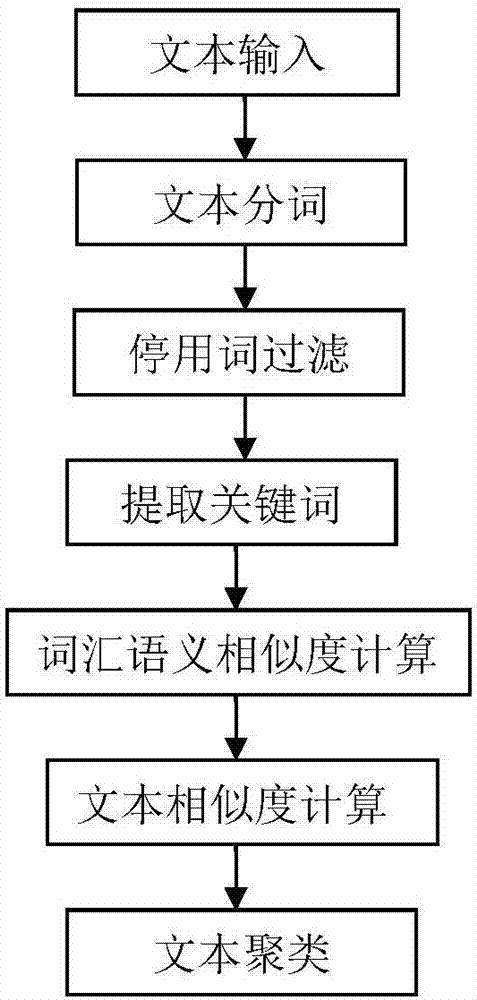
[0041] refer to figure 1 , a density-based text clustering method proposed by the present invention includes the following steps:
[0042] Step A, according to the data set, the text is segmented and the stop words are removed;
[0043] Step B, according to the obtained text word segmentation, according to the three kinds of parts of speech and word frequency of noun, verb, adjective, the corresponding keywords are extracted to the word segmentation;
[0044] Step C, calculating the keyword similarity of the text by using the improved HowNet vocabulary similarity algorithm according to the obtained keywords;
[0045]Step D, calculate the similarity of the text according to the obtained text keyword similarity;
[0046] Step E, according to the obtained text similarity, the text is clustered by a density-based clustering algorithm;
[0047] In the step A, the NLPIR Chinese lexical analysis system of the Institute of Computing Technology of the Chinese Academy of Sciences, na...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More