

Word-splitting method based on Bi-LSTM-CNN
A word segmentation method, bi-lstm-cnn technology, applied in neural learning methods, special data processing applications, instruments, etc., can solve the problems of fewer network layers, low efficiency, low recognition rate, etc., and achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0047] In order to make the above-mentioned features and advantages of the present invention more comprehensible, the following specific embodiments are described in detail in conjunction with the accompanying drawings.
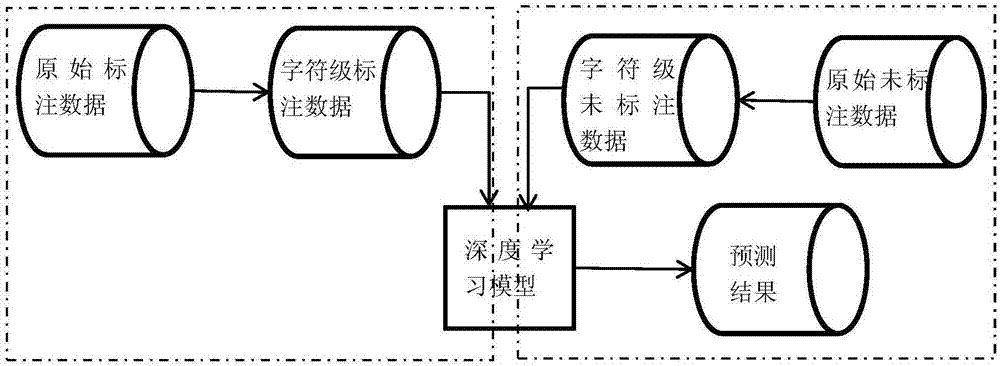
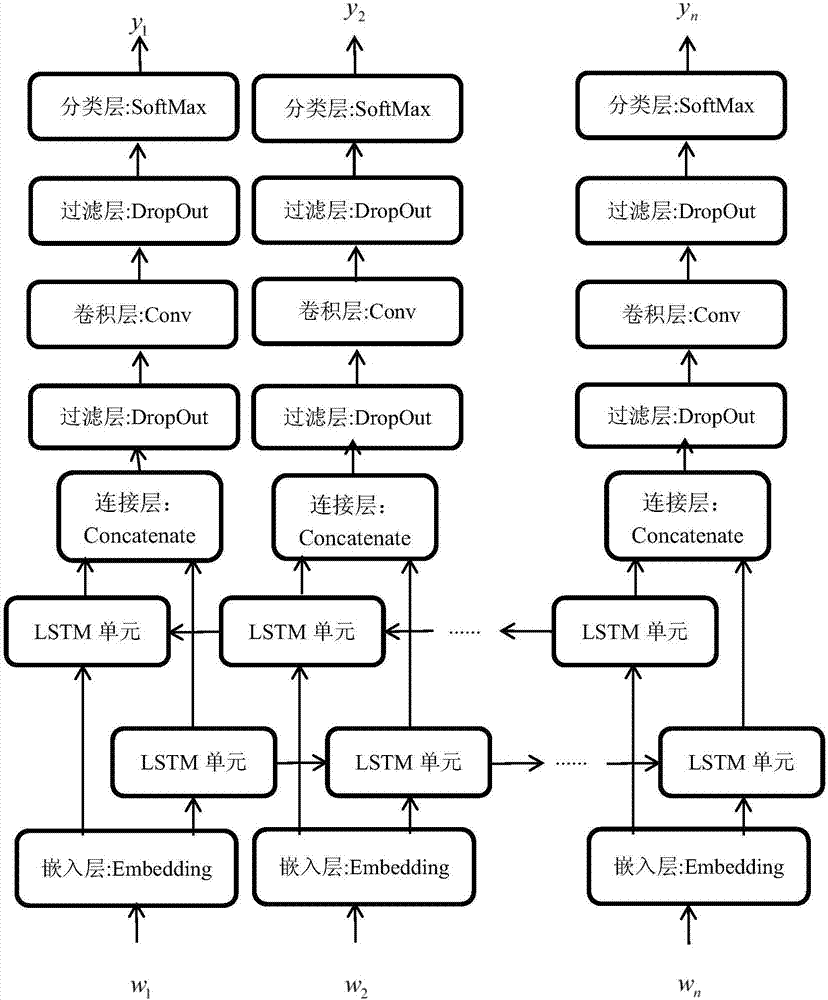
[0048] The method process of the present invention is as figure 1 shown, which includes:
[0049] (1) Training stage:
[0050] Step 1: Transform the original training corpus data OrgData into character-level corpus data NewData. Specifically: using the BMES (Begin, Middle, End, Single) marking method, each word with a label in the original training corpus data is segmented at the character level. Then the character at the beginning of the word is marked as B, the character at the middle of the word is marked as M, the character at the end of the word is marked as E, and if the word has only one character, it is marked as S.
[0051] Step 2: Count the characters in NewData to obtain a character set CharSet. For example, suppose there are two words: Zhonghua...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More