

Distributed massive data processing method and device
A massive data processing and distributed technology, applied in digital data processing, special data processing applications, other database retrieval, etc., can solve problems such as large index cost, global index imbalance, system index and query throughput reduction, etc. To achieve the effect of improving storage efficiency and improving retrieval efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0049] The method in this embodiment is applicable to the client.
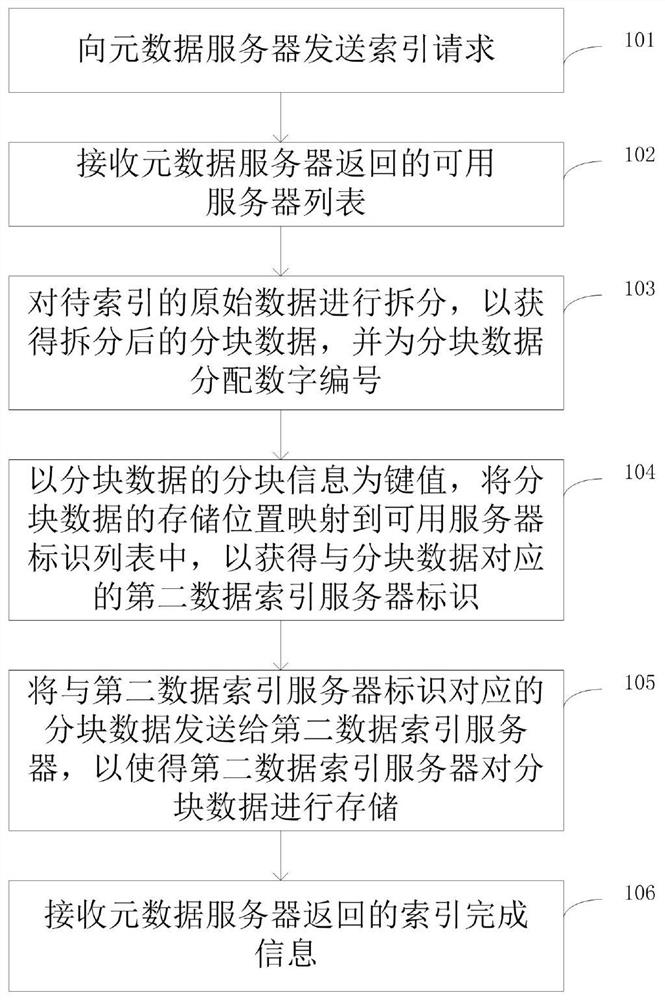
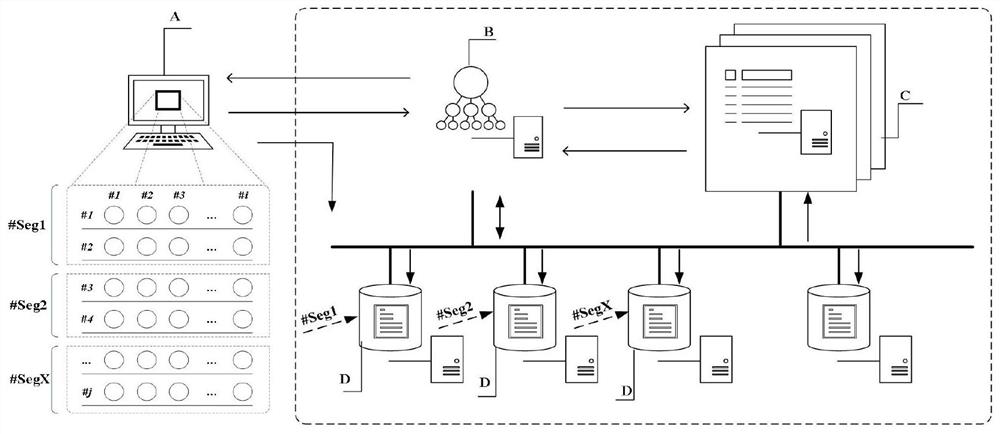
[0050] figure 1 It is a schematic flow chart of the distributed massive data processing method provided by the embodiment of the present invention, figure 2 It is a relationship diagram between various physical devices in the distributed massive data processing method provided by the embodiment of the present invention. Such as figure 1 , figure 2 As shown, the present invention provides a distributed massive data processing method, including step 101-step 106.
[0051] Wherein, in step 101, the client A sends an indexing request to the metadata server B.
[0052] Client A reads the address and port of metadata server B in the locally stored configuration file, and sends an index request to metadata server B to request index data. The metadata server B reads the address and port of the coordination server C through its locally stored configuration file of the coordination server C, and sends a data ind...
Embodiment 2
[0085] The method in this implementation is applicable to the server side. In this embodiment, the server side includes a metadata server B and a first data index server.
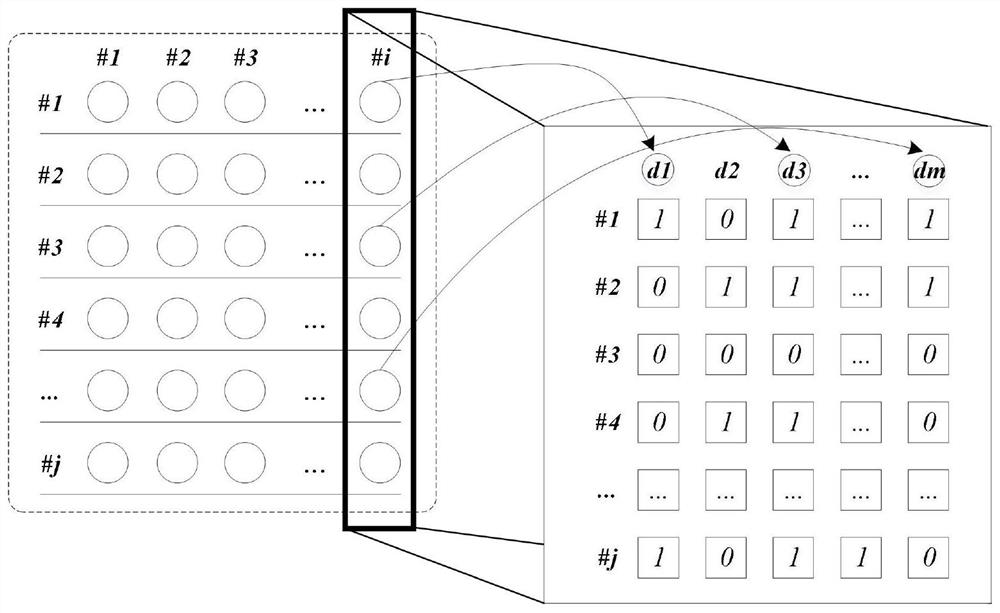
[0086] Image 6 It is a schematic flowchart of the distributed massive data processing method provided by the embodiment of the present invention. As shown in FIG. 6 , the present invention provides a distributed massive data processing method, including steps 201-204.
[0087] In step 201, metadata server B receives an index request sent by client A; the index request includes the number of records included in the original data to be indexed, the number of columns included in each record, and the data type size of each column.
[0088] Step 202, the metadata server B sends the available server list to the client A, the available server list includes one or more first data index server identifiers, and the first data index server identifiers correspond to the first data index server one by one .
[0089]...
Embodiment 3
[0123] This embodiment is an apparatus embodiment corresponding to Embodiment 1, and is used to execute the method in Embodiment 1.
[0124] Figure 8 A schematic structural diagram of a distributed massive data processing device provided in Embodiment 3 of the present invention; Figure 8 As shown, this embodiment provides a distributed massive data processing device, including an index request module 301, an available server list receiving module 302, a split module 303, a storage location acquisition module 304, a block data sending module 305 and index completion information receiving module 306 .
[0125] Wherein, the index request module 301 is configured to send an index request to the metadata server.
[0126] The available server list receiving module 302 is configured to receive the available server list returned by the metadata server; the available server list includes one or more first data index server identifiers, and the first data index server identifier is ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More