

Multi-event natural language description algorithm in video with event relation coding orientation
A technology of natural language and event relationship, applied in computing, computer components, instruments, etc., can solve the problems of inability to obtain event relationship, unsatisfactory effect, and decrease in the accuracy and naturalness of description language, so as to achieve accurate output and less information loss effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

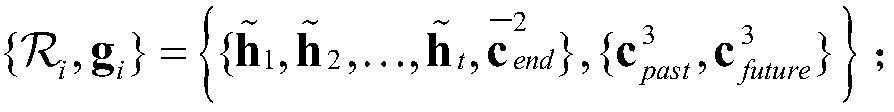
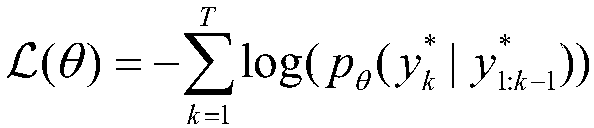
Examples
Embodiment Construction
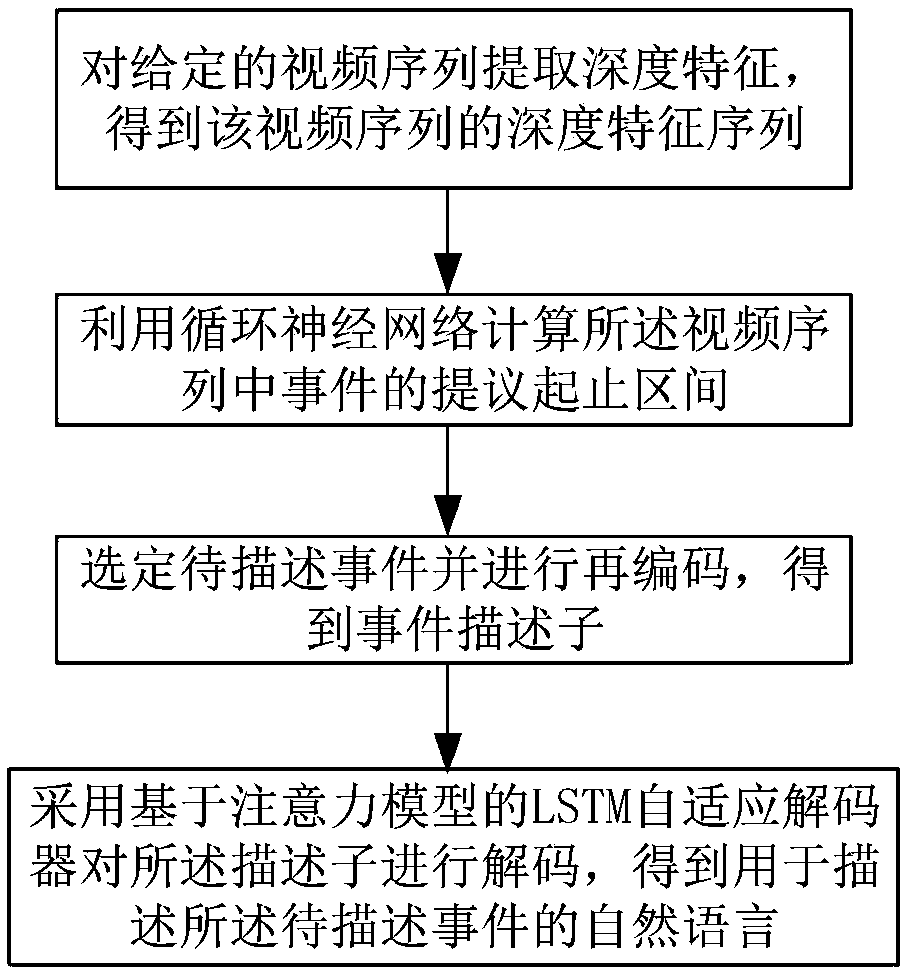
[0020] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
[0021] The specific embodiment of the present invention proposes a multi-event natural language description algorithm in video oriented to event relation coding, refer to figure 1 , the algorithm includes the following steps S1 to S4:
[0022] S1. A three-dimensional convolutional neural network is used to extract depth features from a given video sequence, and several depth feature vectors are obtained to form a depth feature sequence. For a given video sequence, the operation form obtained from the video sequence and event proposal can be written as: in, is the vocabulary sequence of the sentence, p={p start ,p end} is the start and end interval of a given event, Represents a sequence of deep features for a video sequence.
[0023] In order to obtain the depth feature sequence of the video sequence, first, for the given video sequenc...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More