

Multi-speaker voice synthesis method, system and device
A speech synthesis and speaker technology, applied in speech synthesis, speech analysis, instruments, etc., can solve the problems of lack of detailed description of the speaker's pronunciation characteristics, speech synthesis task is not optimal, etc., to improve fine description and provide accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0071] Preferred embodiments of the present invention are described below with reference to the accompanying drawings. Those skilled in the art should understand that these embodiments are only used to explain the technical principles of the present invention, and are not intended to limit the protection scope of the present invention.
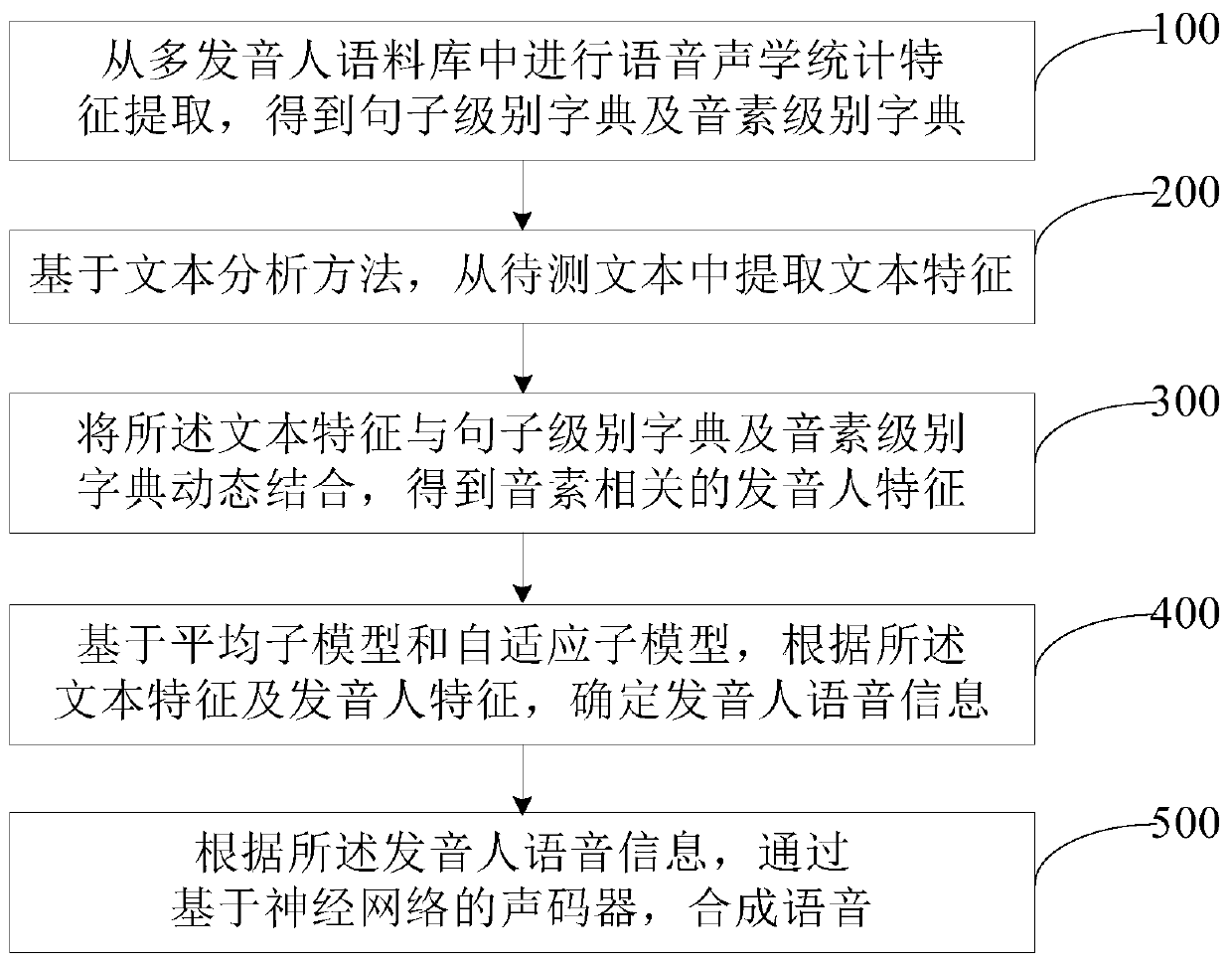
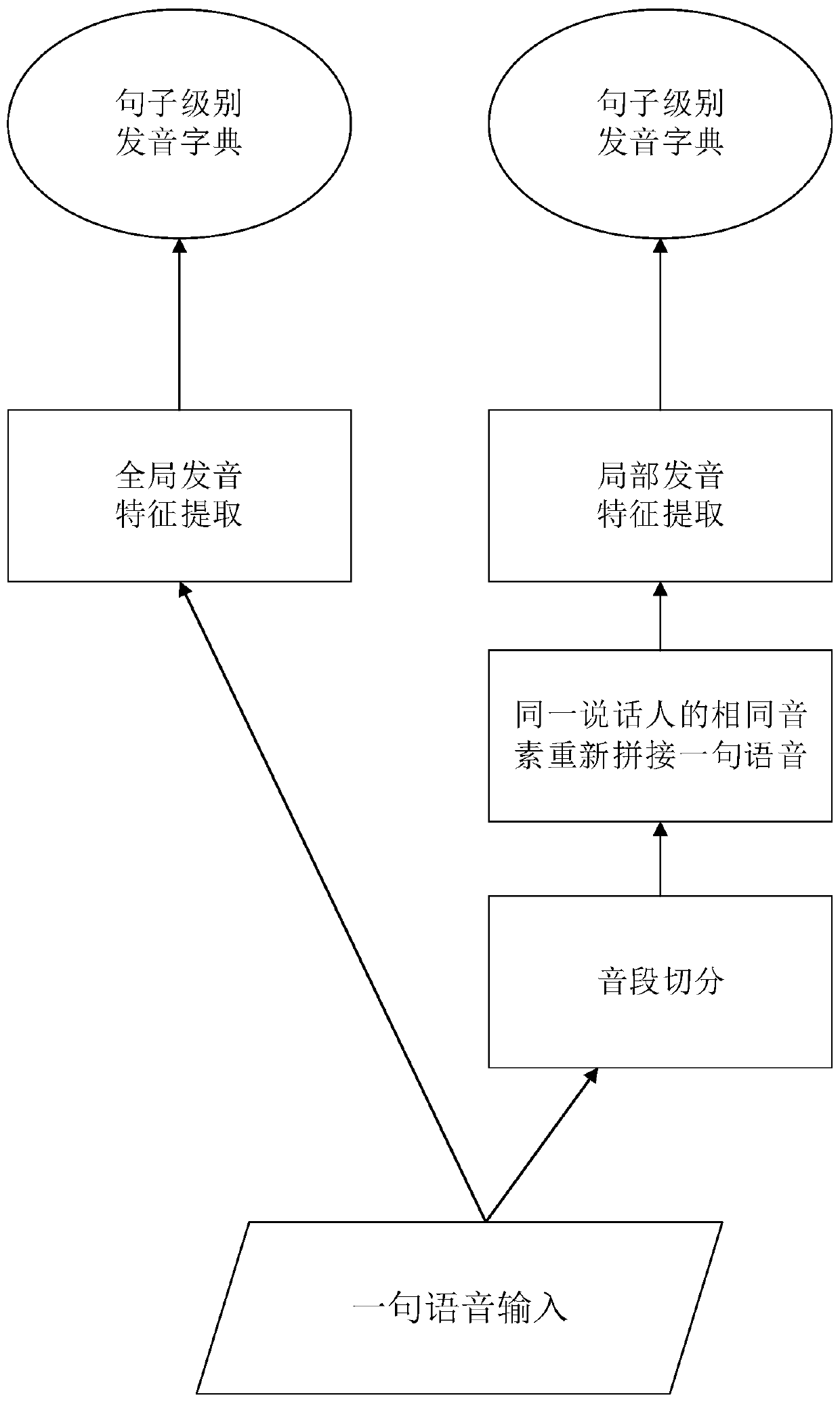
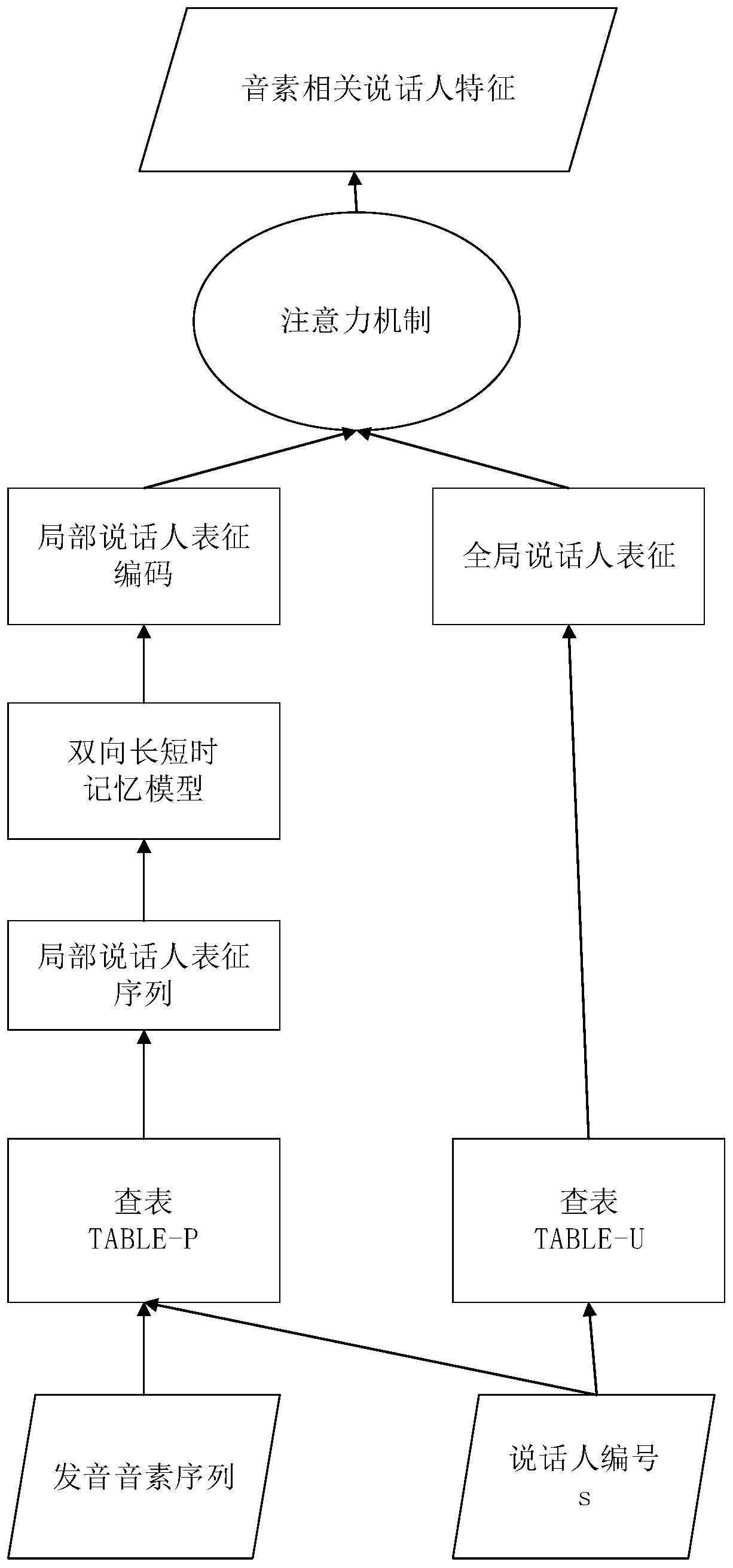
[0072] The present invention provides a multi-speaker speech synthesis method, by extracting text features from the text to be tested, and dynamically combining the text features with sentence-level dictionaries and phoneme-level dictionaries to obtain phoneme-related speaker features, thereby improving A detailed description of the pronunciation characteristics of the speaker; further, according to the text features and the characteristics of the speaker, determine the voice information of the speaker; and then synthesize the voice through the vocoder based on the neural network, so as to effectively improve the accuracy of speech synthesis. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More