

Expression synthesis method, device and computer storage medium based on phoneme drive
An expression synthesis and phoneme technology, applied in the field of image processing, can solve the problems of unable to obtain expression synthesis video, fixed scene, lack of background, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
no. 1 example
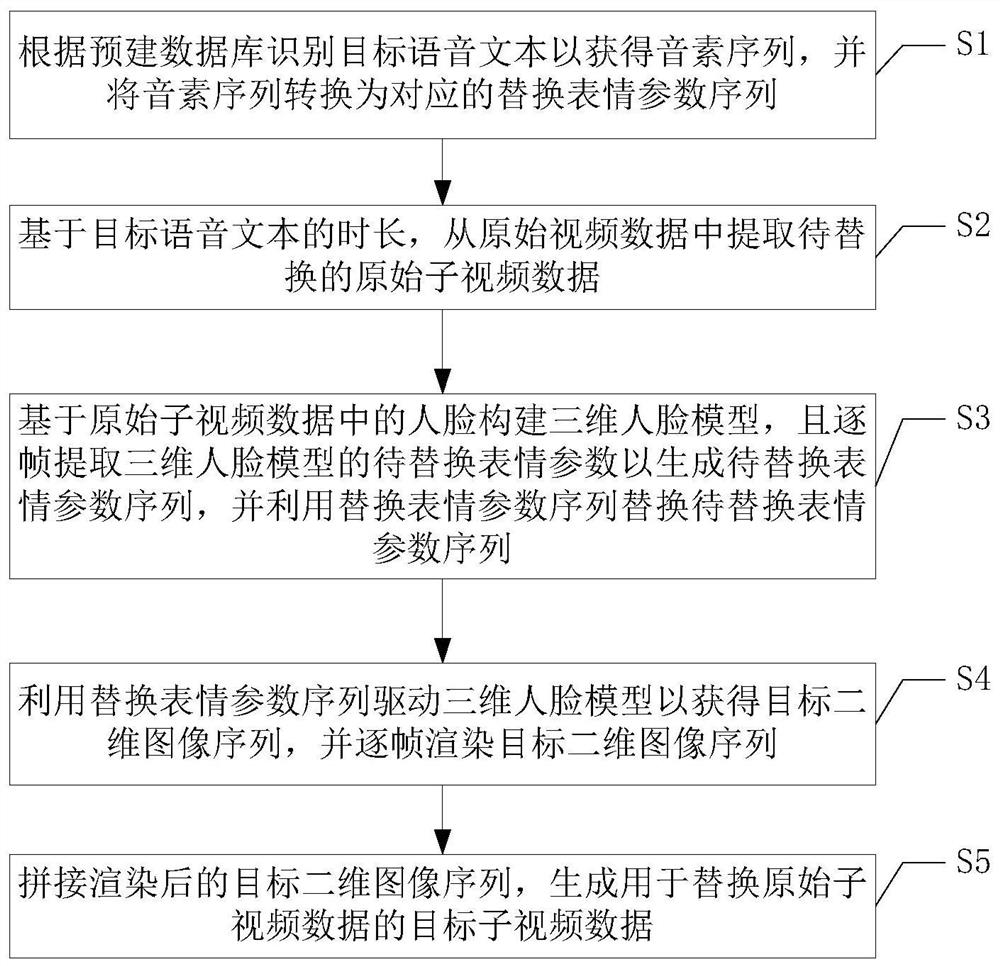
[0033] figure 1 A schematic flowchart of the phoneme-driven expression synthesis method according to the first embodiment of the present invention is shown. like figure 1 As shown, the phoneme-driven expression synthesis method of this embodiment mainly includes the following steps:
[0034] Step S1, identify the target speech text according to the pre-built database to obtain a phoneme sequence, and convert the phoneme sequence into a corresponding replacement expression parameter sequence.
[0035] Optionally, the target voice text in this embodiment of the present invention refers to a voice file recorded in a text form, which is, for example, any existing voice text file, or may be generated by converting audio files by using audio-to-text software. Speech text file.
[0036] Optionally, the audio file may be an existing voice resource or a voice resource generated by temporary recording. In addition, the audio-to-text software may be audio conversion software known to...
no. 2 example
[0053] image 3 A schematic flowchart of the phoneme-driven expression synthesis method according to the second embodiment of the present invention is shown.
[0054] In this embodiment, the above-mentioned recognizing the target speech text to obtain a phoneme sequence, and converting the phoneme sequence into a replacement expression parameter sequence according to a pre-built database (ie step S1) may further include:
[0055] Step S11, editing the correspondence between each phoneme data and each replacement expression parameter to generate a pre-built database.
[0056] Optionally, the above step S11 further includes the following processing steps:
[0057] First, step S111 is executed to construct the phoneme data in the pre-built database.
[0058] In the prior art, the extracted phonemes generally include 18 vowel phonemes and 25 consonant phonemes, for a total of 43 pronunciation phonemes, as shown in Table 1 below, plus silent phonemes, a total of 44 phonemes.
[...
no. 3 example
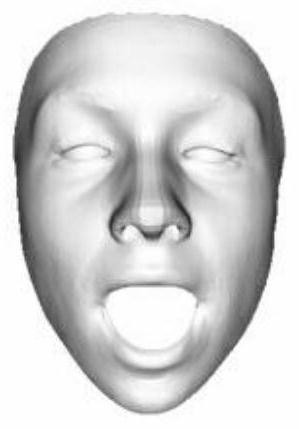
[0080] Figure 4 A schematic flowchart of the phoneme-driven expression synthesis method according to the third embodiment of the present invention is shown.
[0081] In an optional embodiment, the frame-by-frame rendering of the target two-dimensional image sequence (ie, step S4) may further include the following processing steps:
[0082] Step S41, acquiring a target two-dimensional image corresponding to the current frame in the target two-dimensional image sequence and performing rendering processing.
[0083] Step S42, repeating step S41, that is, acquiring a target two-dimensional image corresponding to the current frame in the target two-dimensional image sequence and performing rendering processing, until all target two-dimensional images corresponding to each frame in the target two-dimensional image sequence are The images are all rendered.
[0084] please continue Figure 5 , in an optional embodiment, the above-mentioned acquiring a target two-dimensional image ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More