

Unbalanced data set preprocessing method based on neighborhood information
A technology of neighborhood information and data sets, which is applied in the fields of electrical digital data processing, special data processing applications, digital data information retrieval, etc. It can solve problems such as imbalance, unsatisfactory classification results, and low recall rate of minority classes. , to achieve high precision, expand information expression ability, and reduce the possibility of over-fitting phenomenon
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

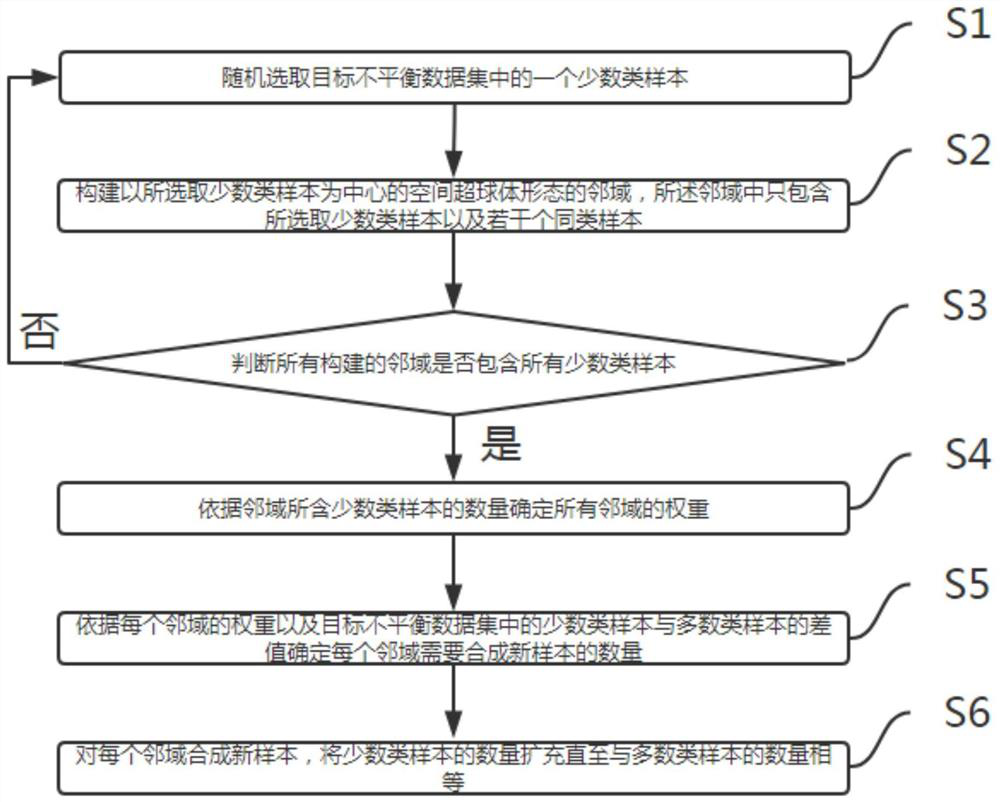
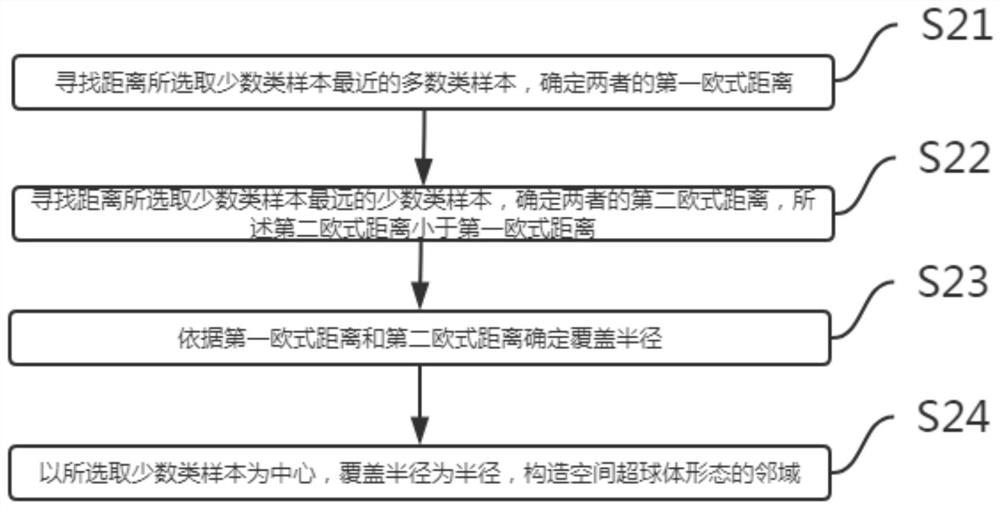
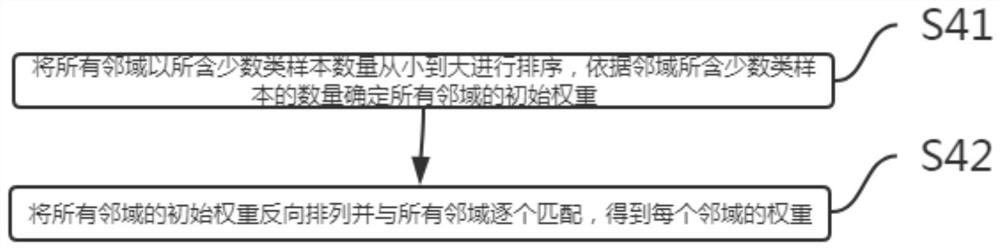
Examples
Embodiment Construction
[0033] In order to make the purpose, technical solutions and advantages of the present disclosure clearer, the present disclosure will be further described in detail below in conjunction with specific embodiments.
[0034] It should be noted that, unless otherwise defined, the technical terms or scientific terms used in one or more embodiments of the present specification shall have ordinary meanings understood by those skilled in the art to which the present disclosure belongs. "First", "second" and similar words used in one or more embodiments of the present specification do not indicate any order, quantity or importance, but are only used to distinguish different components. "Comprising" or "comprising" and similar words mean that the elements or items appearing before the word include the elements or items listed after the word and their equivalents, without excluding other elements or items. Words such as "connected" or "connected" are not limited to physical or mechanica...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More