

Recommendation algorithm based on knowledge graph
A knowledge graph and recommendation algorithm technology, applied in computing, neural learning methods, instruments, etc., can solve the problems of sparse interactive data and inaccurate recommendation results, and achieve the effect of enhancing recommendation performance and improving recommendation effect.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0054] The present invention will be specifically introduced below in conjunction with the accompanying drawings and specific embodiments.
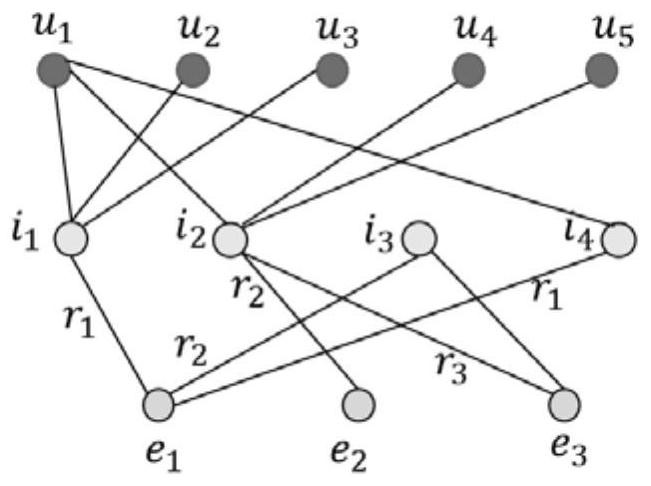
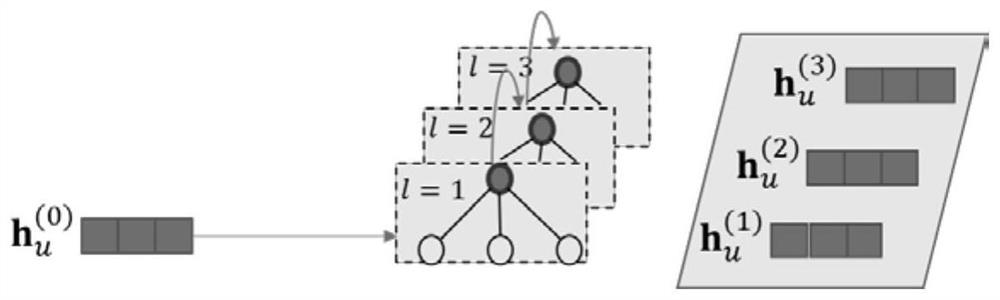
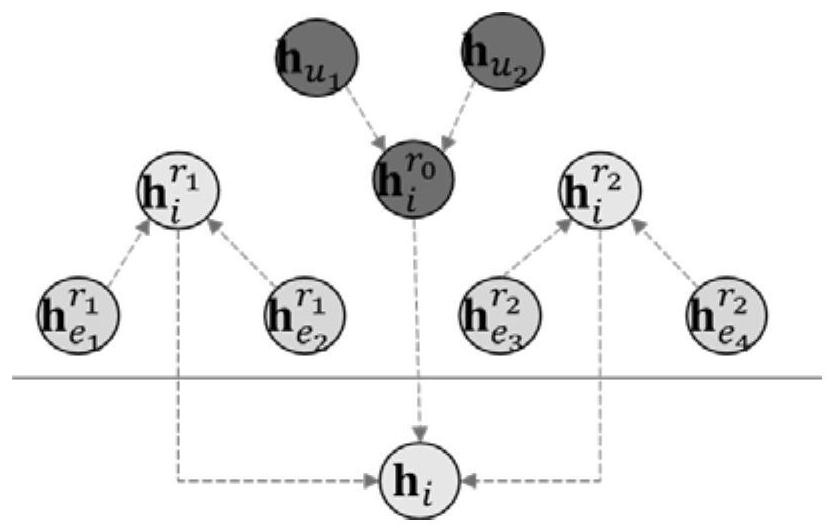
[0055] This application discloses a recommendation algorithm based on knowledge graphs, which includes the following steps: constructing knowledge graphs based on application scenarios; constructing KGRN models based on GNN; inputting knowledge graphs into KGRN models to obtain embedding vectors and expressing users' preferences for items according to the embedding vector output The degree of recommendation indicators; according to the recommendation indicators to recommend operations to users. The recommendation algorithm based on the knowledge map of this application constructs a high-quality knowledge map according to the specific scene recommended. After obtaining the historical data of user-item interaction, user-related information, and item-related attributes in the recommendation scenario, we perform knowledge extraction to obtain...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More