

Speech recognition method and system based on comparative predictive coding
A technology of speech recognition and predictive coding, applied in speech analysis, instruments, etc., can solve problems such as distortion, affecting classification results, and missing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0067] In order to further understand the content, characteristics and effects of the present invention, the following embodiments are exemplified and described in detail below in conjunction with the accompanying drawings.
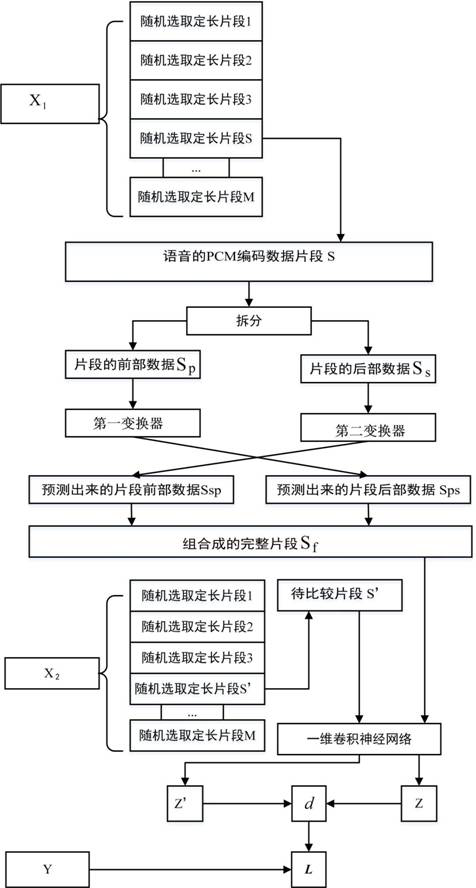
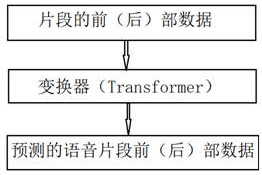
[0068] see Figure 1 to Figure 4 , a speech recognition method based on contrastive predictive coding, comprising:
[0069] S1. Collect A voice files of each voice category, and preprocess each voice file to obtain PCM-encoded voice time series data; A is a natural number greater than 1;
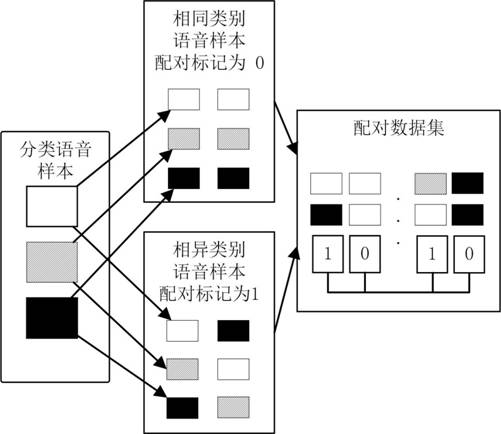
[0070] S2. Construct a paired data set of the voice time series data; the paired data set includes N triples (X 1 , X 2 , Y); where: X 1 is the first voice sequence data of the triplet, X 2 It is the second voice time series data of the triplet, the label Y is defined as 0 when the same pair is paired, and the label Y is defined as 1 when the heterogeneous pair is paired; each data in the same pairing set and each data in the heterogeneous pairing set are composed o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More