Voice operation device, method and recording medium for recording voice operation program
A technology of speech synthesis and sound quality, which is applied in speech synthesis, speech analysis, infrastructure engineering, etc., and can solve problems such as the difference between sound quality and speech content
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035] Embodiments of the present invention will be described below with reference to the drawings.
[0036] A. This embodiment
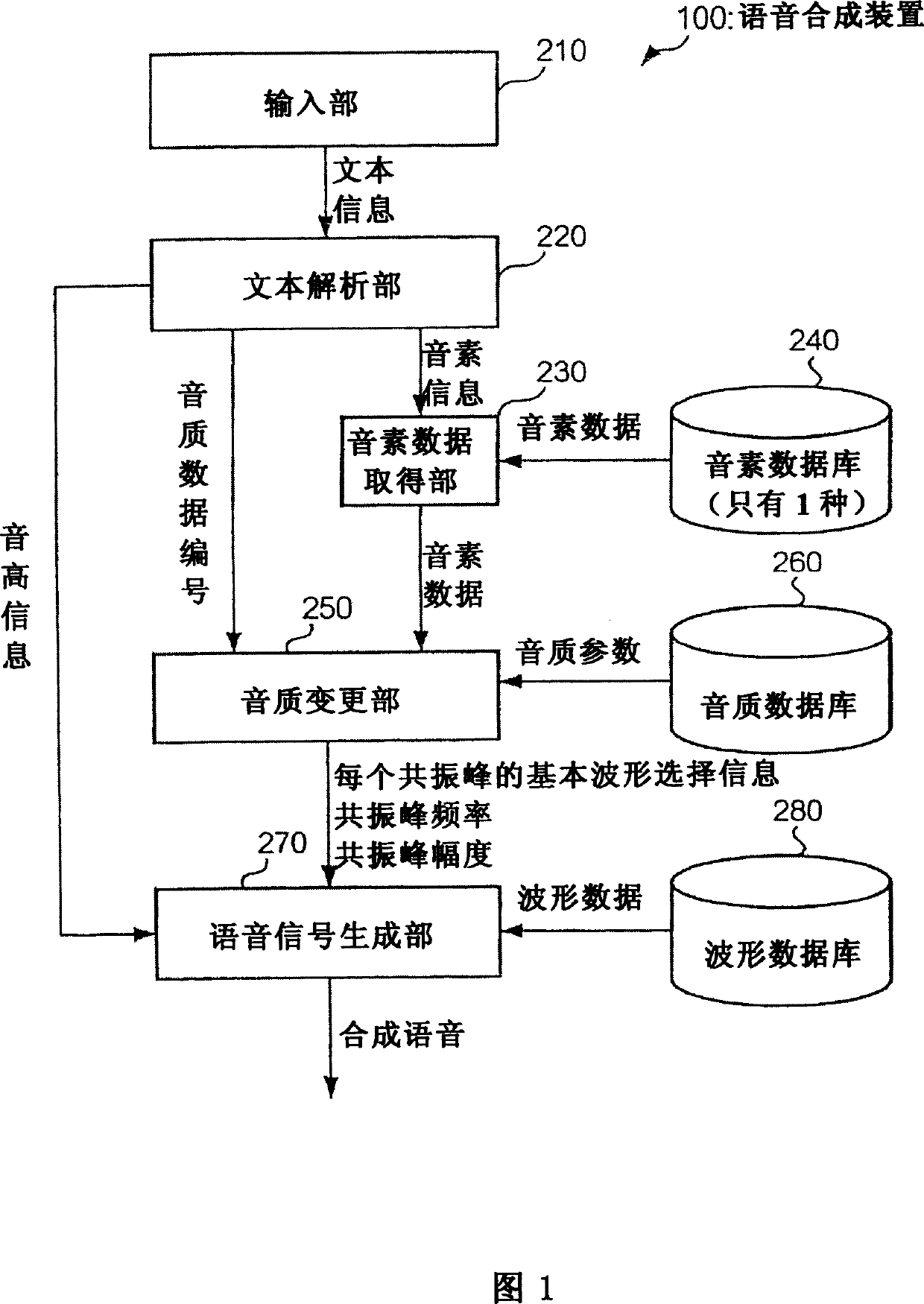
[0037] FIG. 1 is a diagram showing a functional configuration of a speech synthesis device 100 according to the present embodiment. In this embodiment, it is assumed that the speech synthesis device 100 is installed in a mobile terminal such as a mobile phone or PHS (Personal Handyphone System), PDA (Personal Digital Assistance), etc., which have relatively limited hardware resources, but the present invention is not limited thereto. Can be used in various electronic devices.
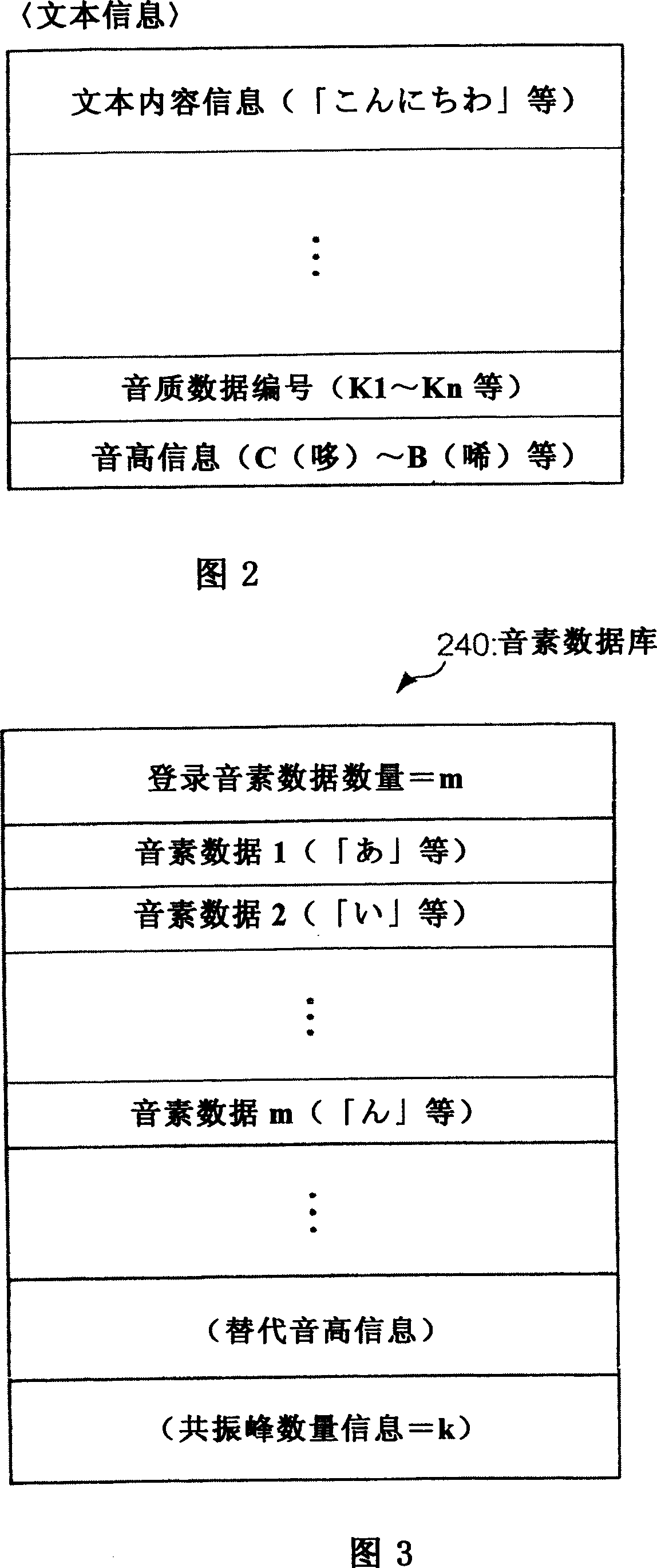
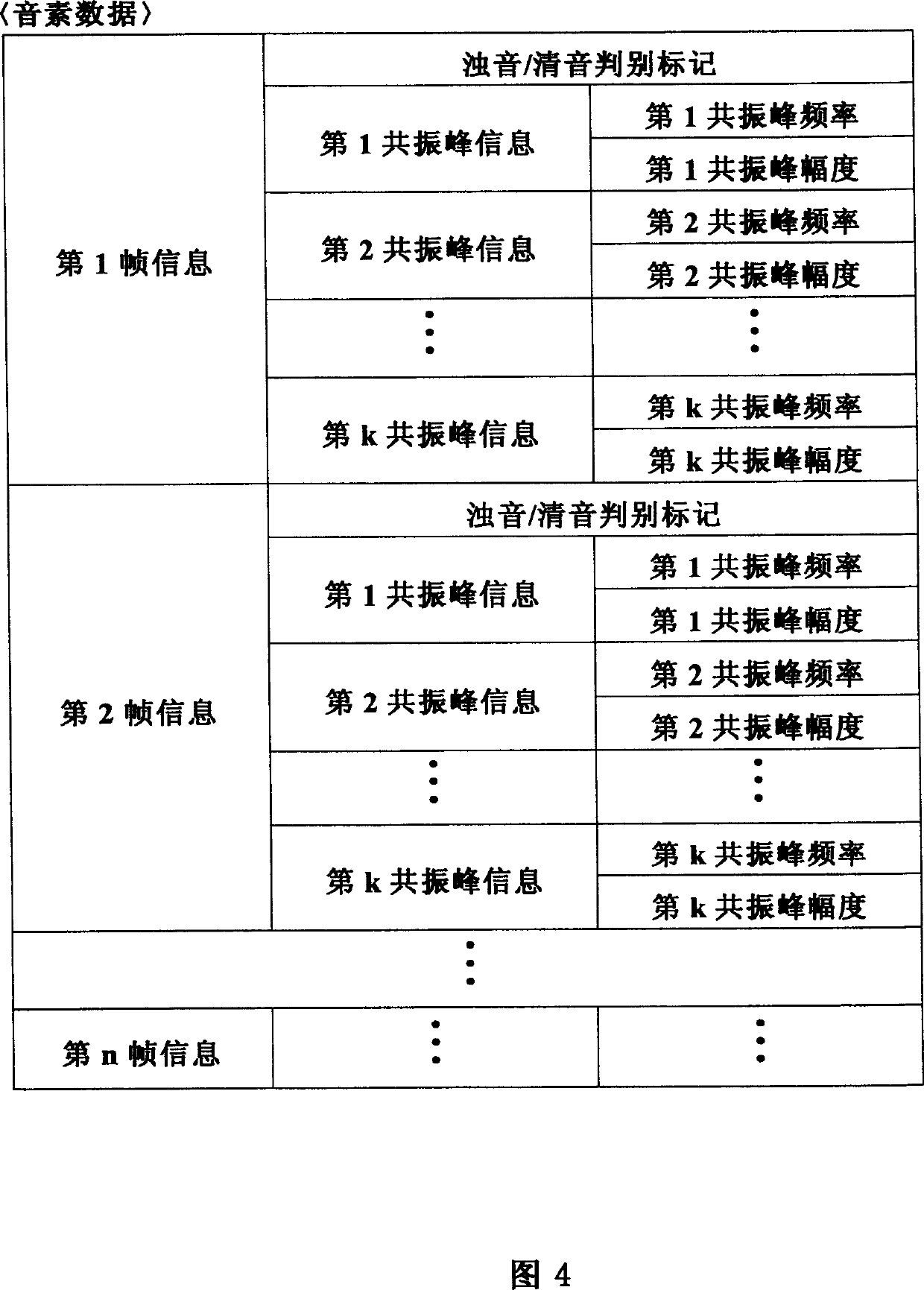
[0038] The input unit 210 supplies text information input via an unillustrated operation unit or the like to the text analysis unit 220 . FIG. 2 is a diagram illustrating text information.
[0039] The text content information is information indicating the content of text to be output as synthesized speech (for example, "こんにちわ"). In addition, in FIG. 2, the text content i...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More