

Multimodal disambiguation of speech recognition
A speech recognition, non-sound technology, applied in the field of speech recognition, can solve the problems of reducing the accuracy of handwriting recognition, slow handwriting typing, and large differences in handwriting styles.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
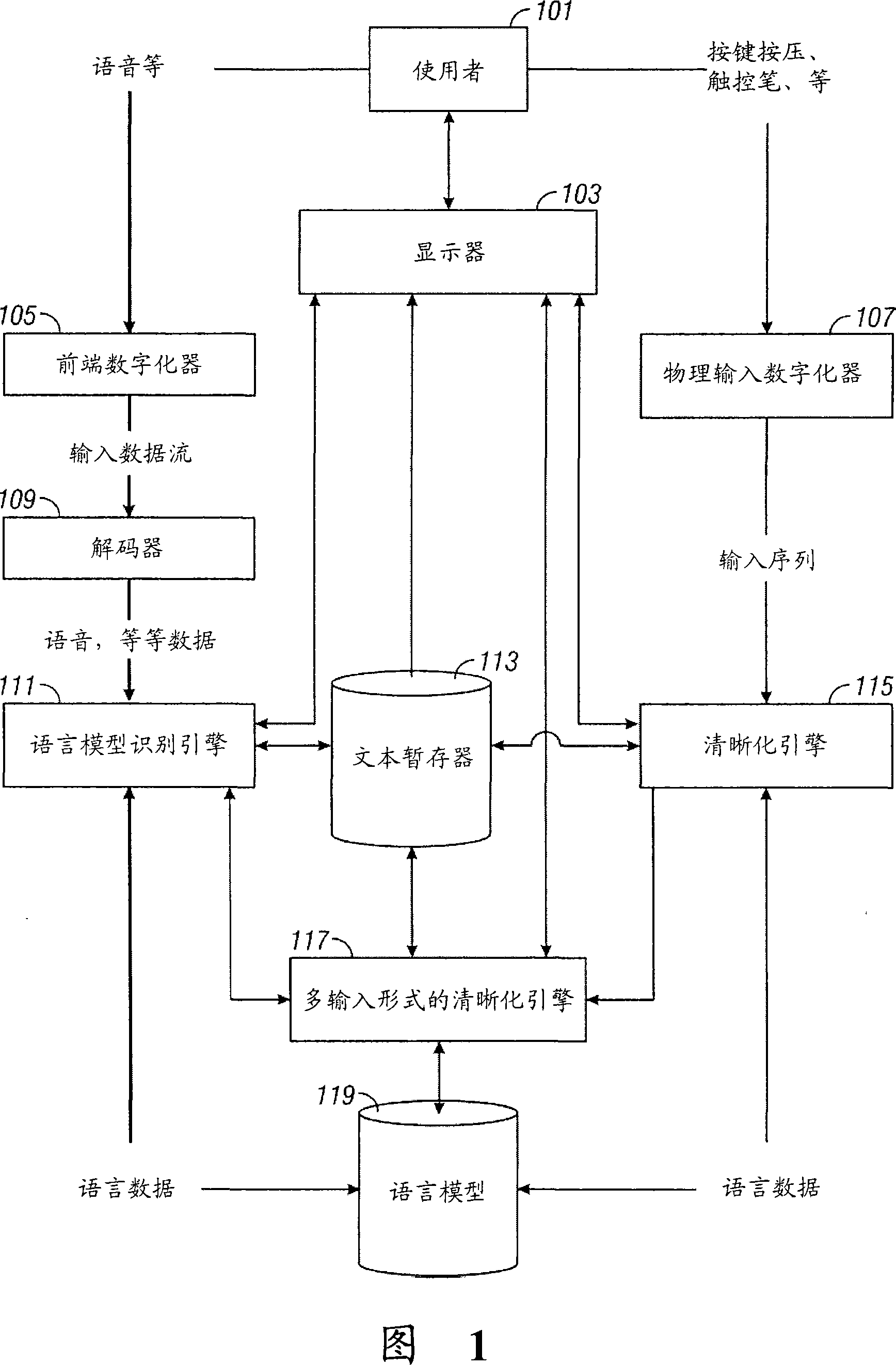
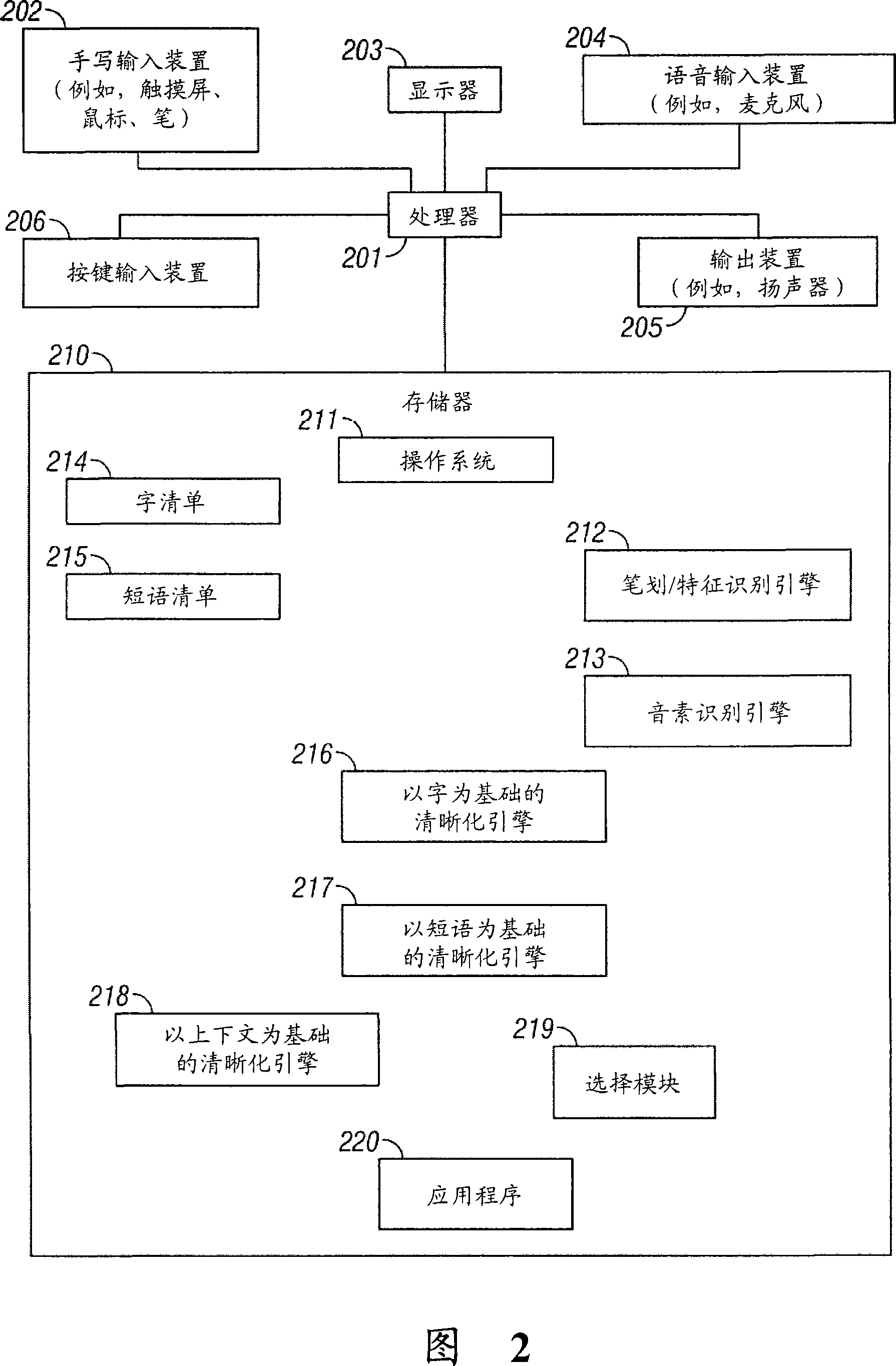
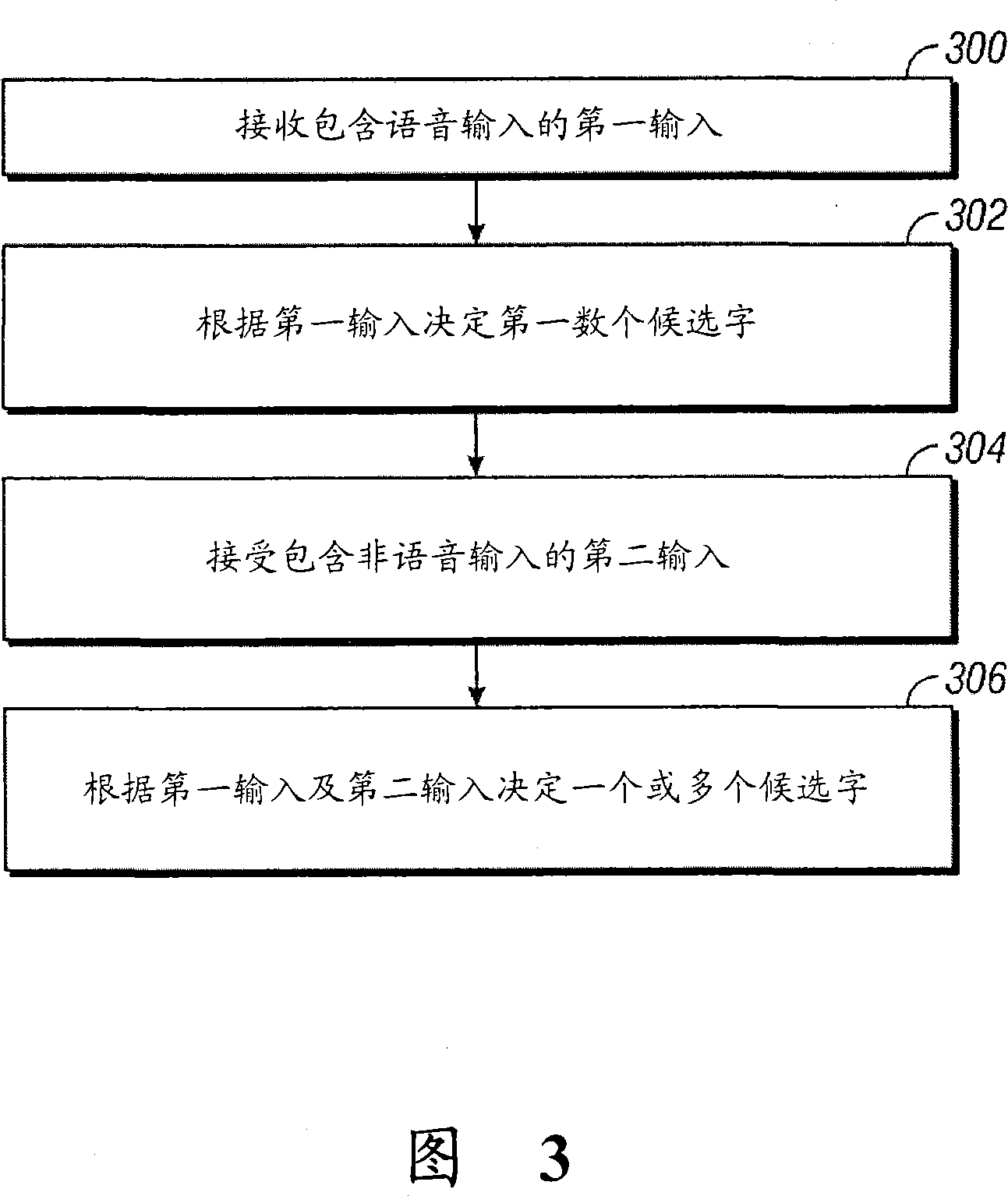
[0063] The present invention provides a device and method for intelligent editing of speech recognition output, which can provide the most likely choice or hypothesis (hypotheses) according to the user's input. The speech recognition engine scores alternative hypotheses that add numerical values to the information presented to the user. For example, if speech recognition provides the user with a wrong first choice hypothesis, the user would want to obtain other N-best hypotheses to modify the hypothesis returned by the recognizer. In a multimodal environment, a list of N best hypotheses from the speech recognition output can be obtained. Specifically, the list of the N best hypotheses is added to the current text menu for easy editing.
[0064] One embodiment of the invention uses both acoustic information and textual context in providing the N best hypotheses. This can be syntactically dependent or independent. That is, a language model may provide grammatical informatio...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More