

Fast implementation of decoding function for variable length encoding
a variable length encoding and decoding function technology, applied in the direction of code conversion, electrical equipment, etc., can solve the problems of reducing the processing time of decoding, data is encoded, and no consideration is given to efficiently encoding data, so as to speed up the decoding of encoded data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
embodiment 1
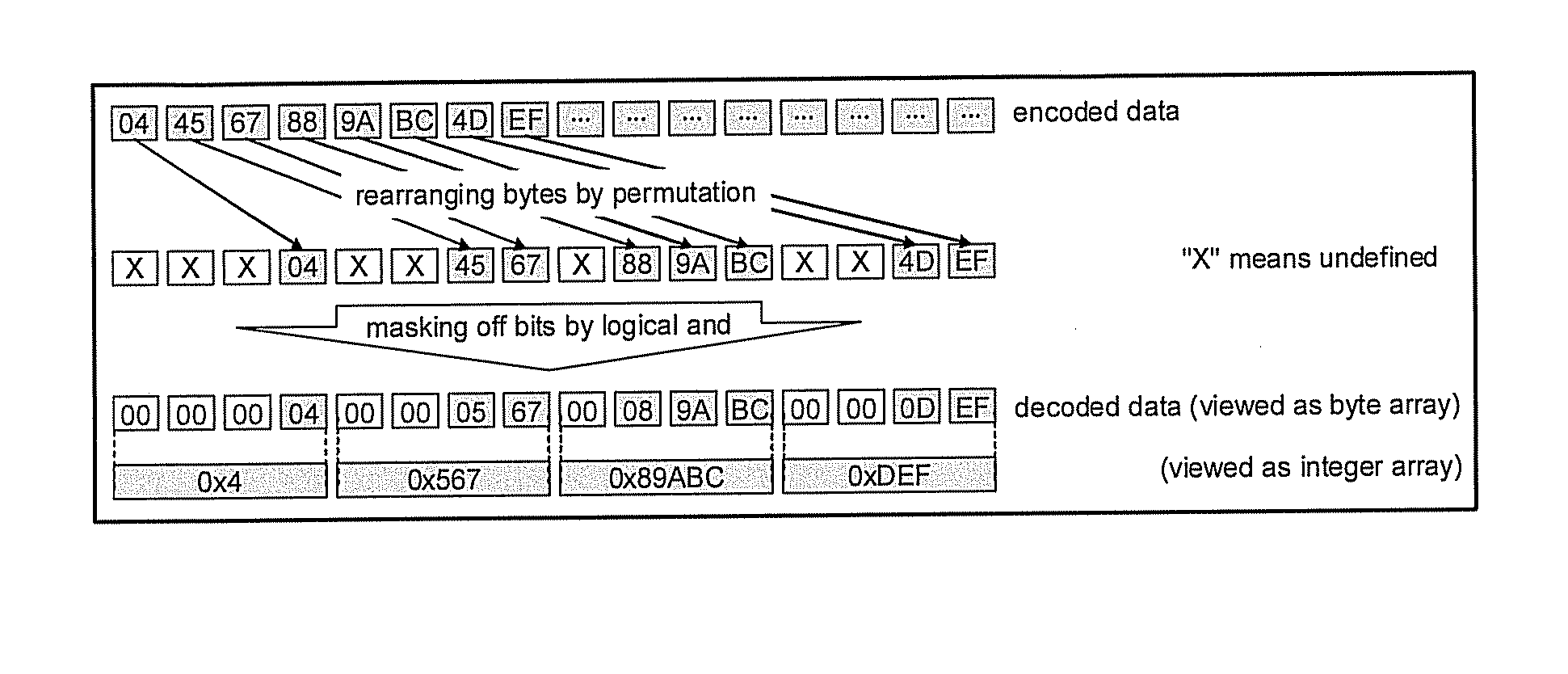
[0037]Conversely, the problem is that a table lookup in block 1004 functionality or operation costs become necessary. In an exemplary embodiment, referred to as embodiment 1 in FIG. 6, using the program in FIG. 4 can perform decoding of the simple encoding of the Table 1 shown above.
[0038]In another exemplary embodiment, referred to as embodiment 2 in FIG. 6, decoding of BER (Basic Encoding Rules) compression can be effectuated. In this regard, a variable length encoding format that is included in ITU-T recommendation X.690 (ITU-T Recommendation X.690, Information technology—ASN.1 encoding rules: Specification of Basic Encoding Rules (BER), Canonical Encoding Rules (CER) and Distinguished Encoding Rules (DER)), and it is widely employed not only in the communication field but also in various fields of application. BER compression is variable length encoding, which shows that in 1 byte of data, the first bit is a flag and the remaining 7 bits are data, and when the flag bit is 1, the...
embodiment 3
[0040]Referring to FIG. 7 there is illustrated one example of example of Steps 2 and 3 of UTF-8 decoding. In an exemplary embodiment, referred to as embodiment 3 in FIG. 7, a more complicated example is shown that decodes text of the UTF-8 encoded UNICODE (UCS-2). In the decoding of UTF-8, data transfer has to be conducted by bit as well. In UTF-8, when expressing the character code of UCS-2, it is encoded into any one of three kinds of encoding; one byte (ASCII character, 0×00-0×7F), two bytes (Latin character, etc., 0×80-0×7FF), or three bytes (Japanese, etc., 0×800-0×FFFF). As an example, when it is encoded into three-byte length data, three-byte UTF-8 data of [1110xxxx], [10yyyyyy], and [10zzzzzz] has to be transformed into two-byte UNICODE characters of [xxxxyyyy] and [yyzzzzzz], which cannot be realized through sorting only in units of bytes.
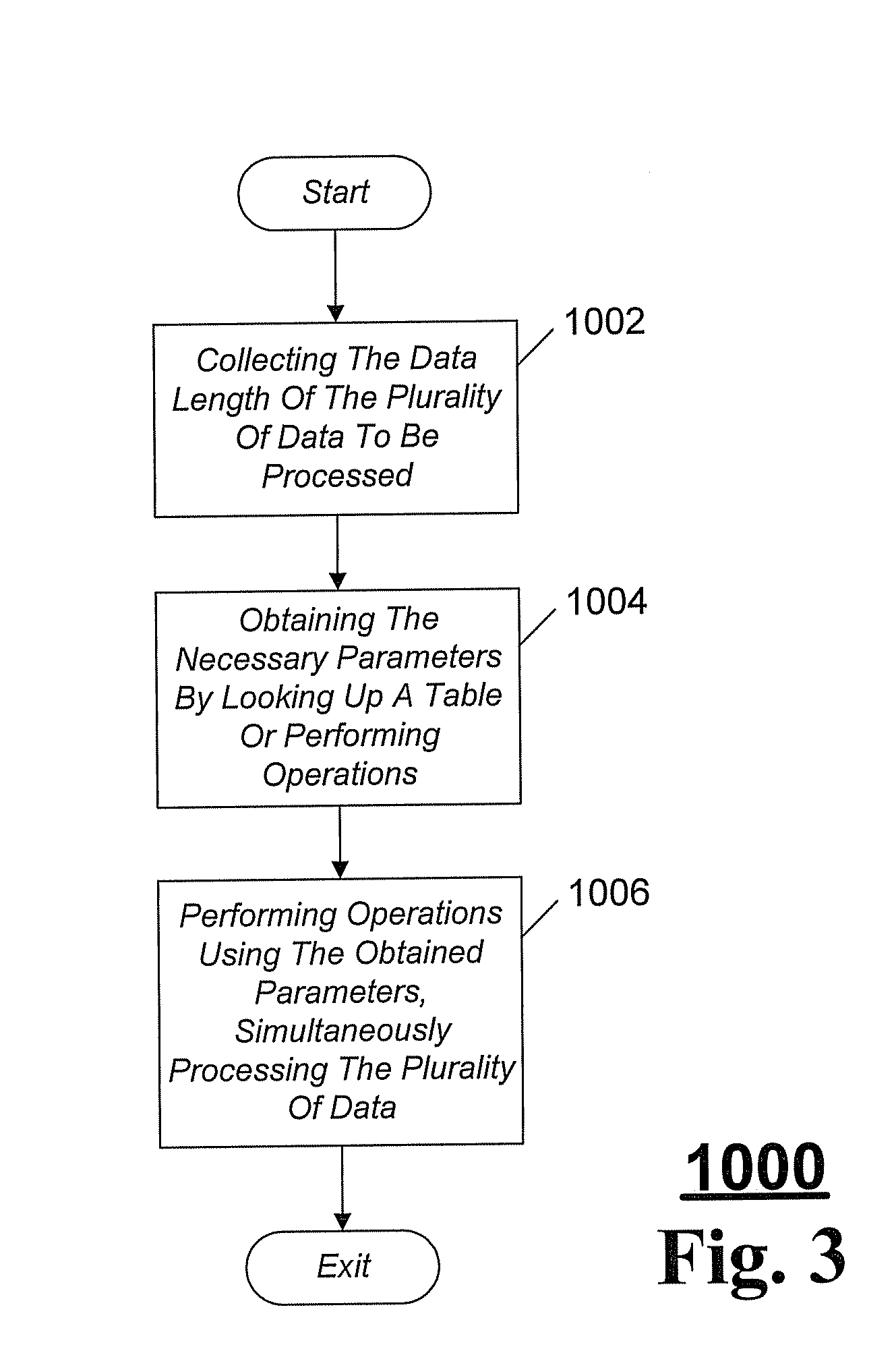
[0041]Even in such a case, although the number of parameters and operations to be performed may increase, routine 1000 of the present inv...
embodiment 2
[0043]The performance of decoding the UTF-8 of embodiment 2, implemented on the PowerPC970, is shown in FIG. 10. The label of the x-axis is the type of document, input size (KB)→output size (KB). The three on the left, among the input data used in the test, are artificial data, and they are input in the form of all 1-byte characters (ASCII text), all 3 byte characters (Japanese text), and repetitions of 1, 2, and 3 bytes. Others are text files in real world (mainly HTML), in which the characters to be encoded into all 1-byte characters and into 2 or 3 bytes are intermingled. The graph shown is the relative performance of the implementation compared to a tuned implementation without the method of the present invention. When using the method of the present invention, higher performance is obtained for all documents.
[0044]The capabilities of the present invention can be implemented in software, firmware, hardware or some combination thereof.
[0045]As one example, one or more aspects of ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More