Video virtual hand language system facing digital television
A technology of digital TV and virtual human, applied in the field of video virtual human sign language system, to achieve the effect of natural action, balance of imaging quality and operation efficiency, and saving manpower and material resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0032] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only some, not all, embodiments of the present invention. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
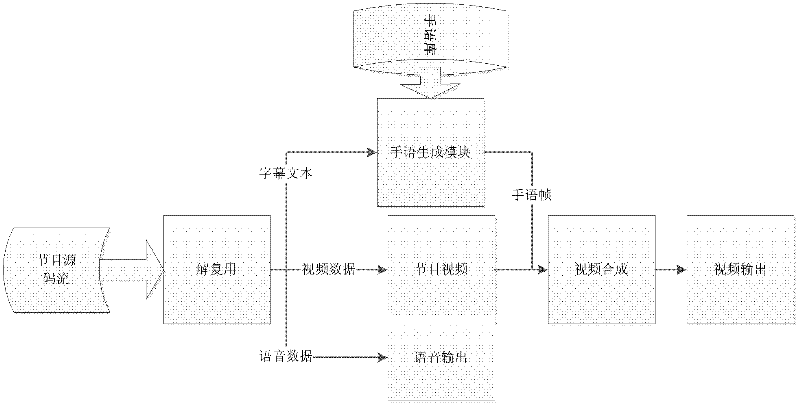
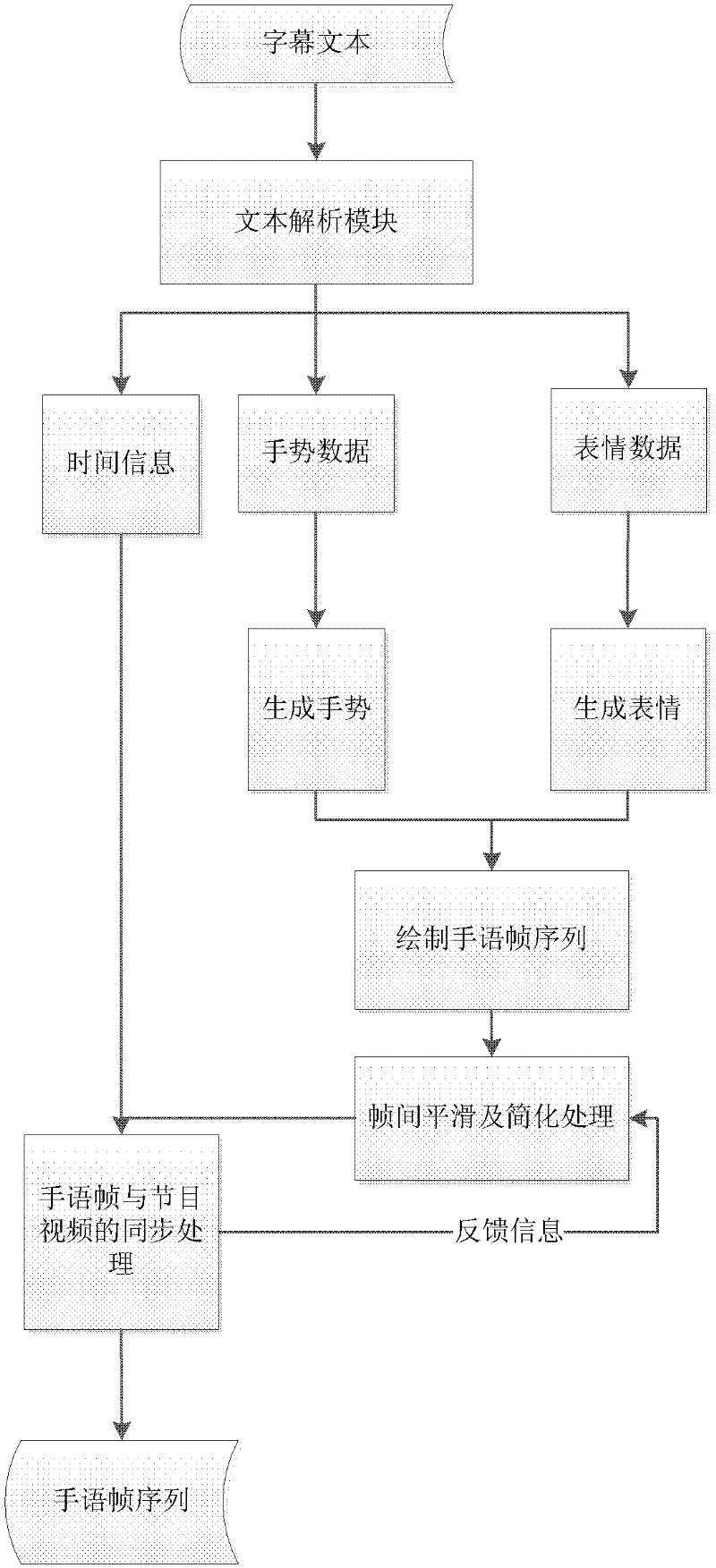
[0033]Embodiments of the present invention provide a digital television-oriented video avatar sign language system, which can save manpower and material resources and be accurate and standardized, and will be described in detail below.
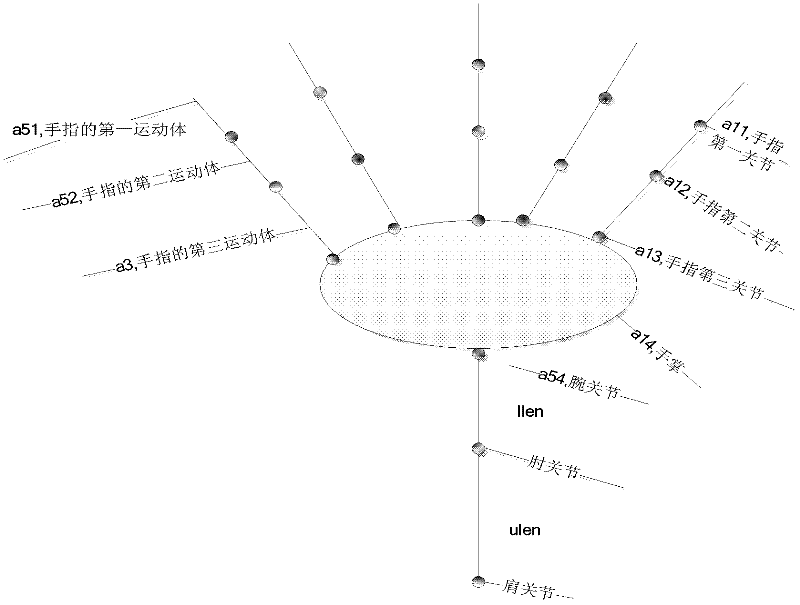
[0034] The purpose of the present invention is to solve the above-mentioned defects in the prior art and provide a virtual human-based sign language system with better effect. The main problems to be solved are: (1) synchronous pro...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com