Clustering-based big data normal-mode extracting method and system
A big data and pattern technology, applied in database models, relational databases, electrical digital data processing, etc., can solve problems such as mixed attribute values of different samples, no exact rules, difficult to study the time series relationship of related clusters, etc., and achieve analysis results Stable and reliable, reducing the effect of calculation results
Active Publication Date: 2014-11-19
CHINA NAT SOFTWARE & SERVICE
View PDF4 Cites 16 Cited by
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
[0005] (1) The mainstream clustering algorithm does not give an exact classification standard. In the clusters obtained based on distance, the attribute values of different samples are mixed, and there is no exact rule. It is possible that 99 of the 100 samples in a certain cluster are "Gender=male", only one is "gender=female", which makes the practical guidance of the classification results poor
[0006] (2) For a class of complex trend data samples, such as the daily shopping situation of customers in a supermarket, the c
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View moreImage
Smart Image Click on the blue labels to locate them in the text.
Smart ImageViewing Examples



Examples
Experimental program
Comparison scheme
Effect test
 Login to View More
Login to View More PUM
 Login to View More
Login to View More Abstract
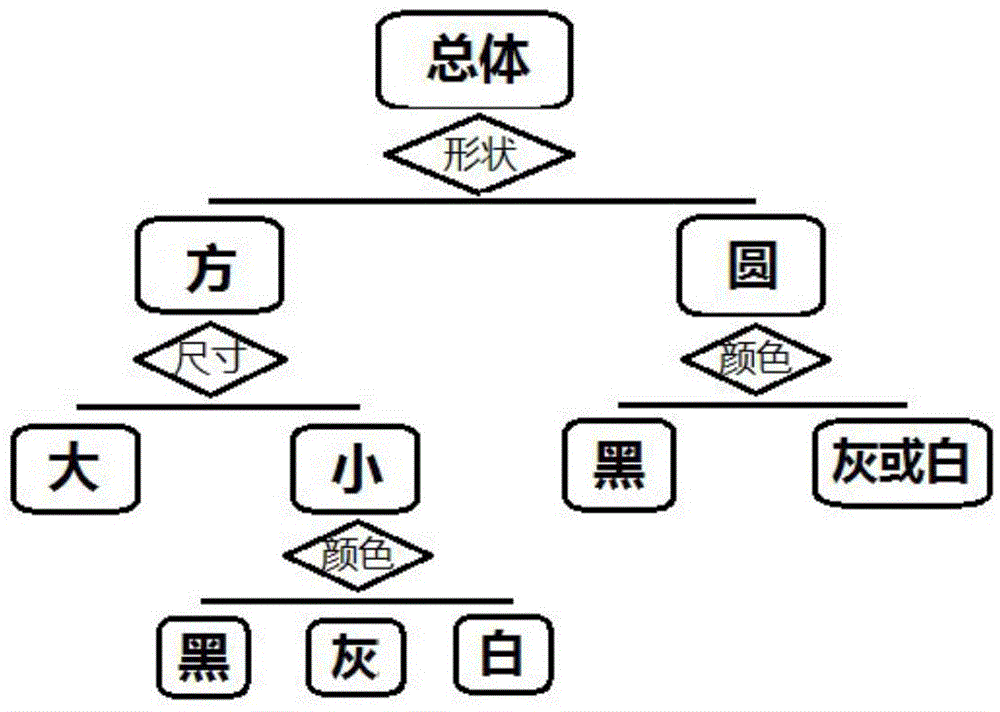
The invention discloses a clustering-based big data normal-mode extracting method and system. The clustering-based big data normal-mode extracting method includes steps of 1) acquiring sample data from terminals by a server to obtain a total sample data set; 2) extracting a plurality of samples from the total sample data set, clustering the samples to obtain clusters as labels of the samples and marking the samples, calculating four indexes including attribute value identification, attribute identification and/or attribute value importance and attribute importance of each attribute of the marked samples in the sample set according to selected attribute dimensionality reduction indexes; sequencing the attributes according to a calculation result and selecting a plurality of attributes as remained attributes after dimensionality reduction of big data; 3) clustering all sample data after dimensionality reduction of the attributes to obtain clusters as labels of the samples and marking the samples; 4) calculating the four indexes of each attribute of the marked samples according to selected attribute partition indexes, selecting a plurality of attribute characteristics to partition the total sample data set, and taking a partition result as a normal mode.
Description
technical field [0001] The invention relates to a normal pattern extraction system, in particular to a clustering-based big data normal pattern extraction method and system. Background technique [0002] In real life, we often need to classify a set of sample data. There are two commonly used processing methods: [0003] The first classification method is to determine some classification indicators (attributes, attribute values) based on experience and classify the sample data according to these indicators. Based on the attribute "age class". This classification method strongly depends on the experience of the classifier and has a strong subjective color, so that the classification results obtained by different people for the same set of sample data may be quite different, and it is difficult to determine which classification is more scientific. [0004] The second classification method is based on the clustering results of data mining cluster analysis, and the clustering...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More Application Information
Patent Timeline
 Login to View More
Login to View More IPC IPC(8): G06F17/30
CPCG06F16/285
Inventor 王电魏毅黄煜可
Owner CHINA NAT SOFTWARE & SERVICE
Features
- R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
Why Patsnap Eureka
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Social media
Patsnap Eureka Blog
Learn More Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com