Data processing method and system under Hadoop platform
A data processing and data technology, applied in the field of data processing, can solve the problems of untimely feedback of results, large amount of data query and analysis calculation in data archives, etc., to ensure compatibility, improve data query and analysis efficiency, and save computing resources. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
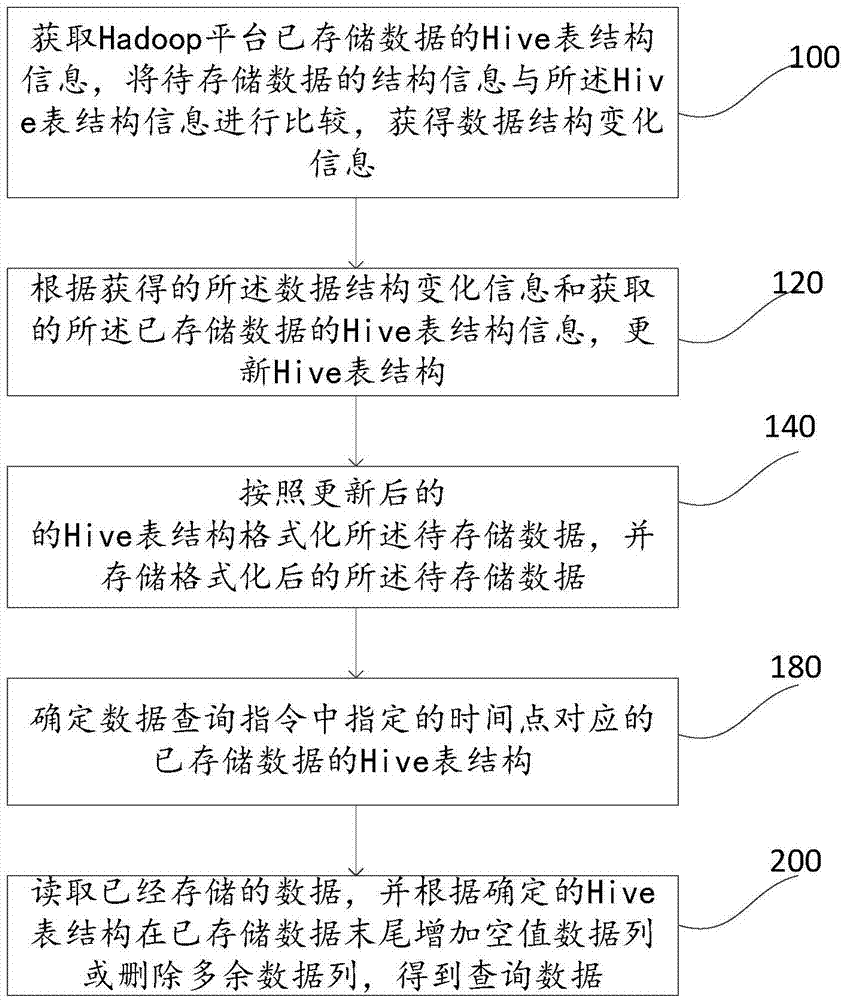
[0050] refer to figure 1 , shows a flowchart of a data processing method under the Hadoop platform of the present application. The method is applied to a scenario where data needs to be archived, stored, and inquired and analyzed, and includes the following steps.
[0051] Step 100, obtain the Hive table structure information of the stock data on the Hadoop platform, compare the structure information of the data to be stored with the Hive table structure information, and obtain data structure change information.
[0052] Wherein, the Hive table structure information of the data at least includes: the attribute of the data column, and the position of the data column. The data structure change information includes: no change, or includes: adding a column, deleting a column, adjusting a column position, any one flag or a combination of multiple flags.
[0053]When the attributes of the data columns in the data structure information of the data to be stored are exactly the same ...
Embodiment 2
[0061] see figure 2 As shown, based on the data processing method in Embodiment 1 of the present application, another embodiment of the present application further includes:
[0062] Step 160, re-store the stored data according to the updated Hive table structure.
[0063] When the data format of the data to be stored is different from the data format of the stock data, that is, when the obtained data structure change information includes the "new column" flag, by adding the corresponding data column after the obtained structure of the stock data, Update the Hive table structure. That is, when the method disclosed in Embodiment 1 of the present application is used for data storage, the data columns of the Hive table may increase with the increase of the data storage capacity and the passage of time. In order to facilitate the compliance management of stored data, preferably, the data structure of all stored data needs to be adjusted to the updated Hive table structure, that...
Embodiment 3
[0067] Based on the data processing method under the Hadoop platform of Embodiment 1 of the present application, in another embodiment of the present application, such as figure 2 shown, also includes:
[0068] Step 180, determine the Hive table structure of the stored data corresponding to the time point specified in the data query instruction;
[0069] Step 200, read the stored data, and add null data columns or delete redundant data columns at the end of the stored data according to the determined Hive table structure to obtain query data.
[0070] When data is archived and stored, when the data format of the data to be stored is different from that of the stock data, that is, when the obtained data structure change information contains the "new column" flag, the structure of the stock data acquired Then add the corresponding data columns and update the Hive table structure, that is, as the amount of data storage increases, the data columns of the Hive table may increase....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com