

A Computer Text Classification System
A text classification and computer technology, applied in text database clustering/classification, unstructured text data retrieval, special data processing applications, etc. Space complexity, ensuring efficiency, and improving the effect of accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
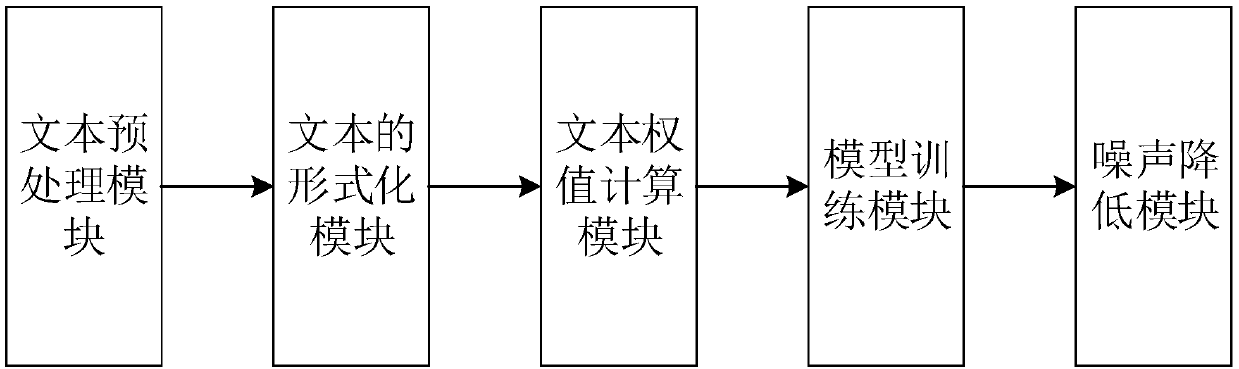
[0052] Such as figure 1 As shown, the present embodiment 1 provides a computer text classification system, including:
[0053] Text preprocessing module, text formalization module, text weight calculation module, model training module, noise reduction module;
[0054] In the text preprocessing module, a dual method is used to remove stop words. The text often reflects the content of the text through content words such as nouns, verbs, and adjectives, while function words and words that often appear in the text but do not indicate the content of the text are called stop words. Since these stop words do not represent the actual meaning of the text, they have no contribution to text classification, on the contrary they will increase the time and space complexity of the classification algorithm to process the text. Therefore, in order to reduce the storage space and improve the classification efficiency and classification accuracy of the text classification algorithm, it is nece...
Embodiment 2
[0058] Text classification is to divide a large number of text documents into one or a group of categories, so that each category represents a different conceptual theme. Text classification is actually a pattern classification task, and pattern classification algorithms can be applied to text classification. Text classification applies natural language processing to it, which is closely related to the semantics of documents, so it has many uniqueness compared with ordinary pattern classification tasks.
[0059] In the high-dimensional feature space, there are a large number of candidate features when extracting document features. If words are used as document features, even a small training document set will generally generate tens of thousands of candidate features. If one item is used as a feature, more candidate features will be generated. Feature Semantic Correlation One solution to avoid bad selection results is to assume that most features are independent of each othe...
Embodiment 3
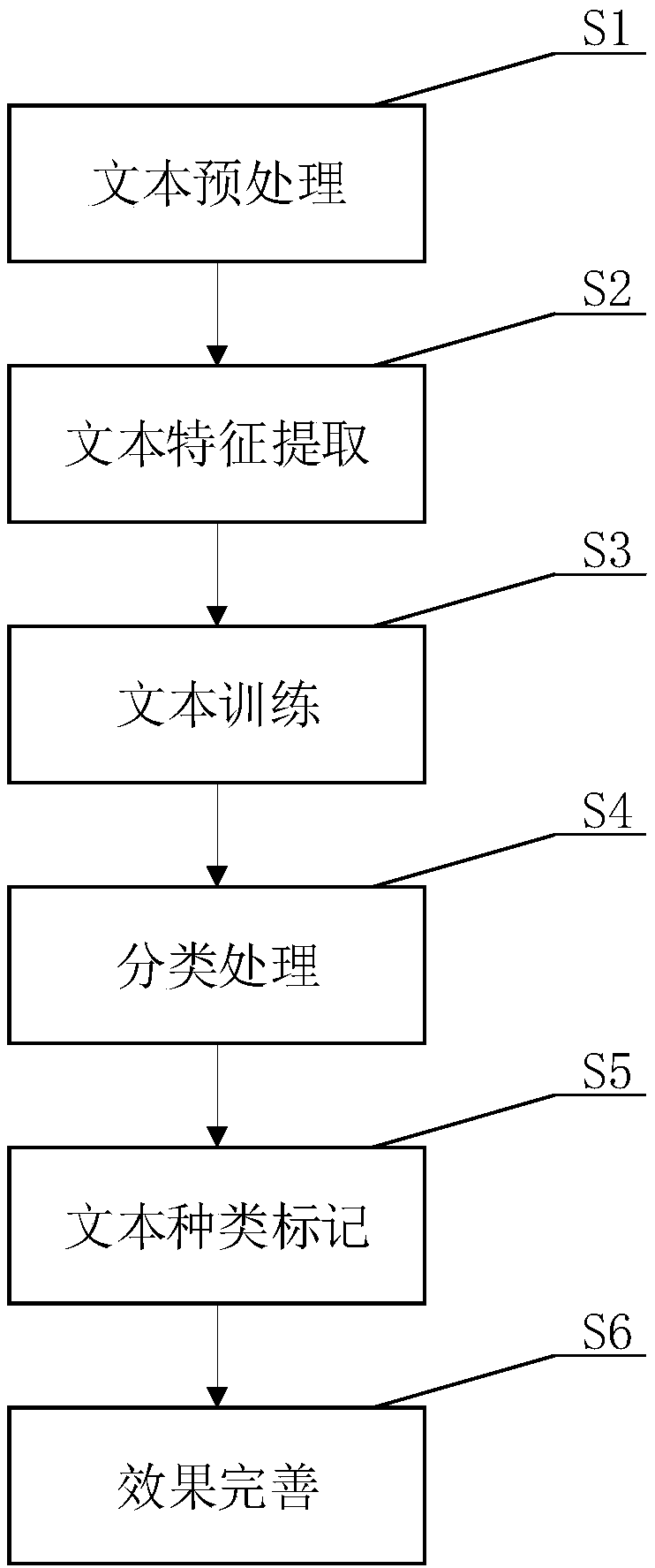
[0062] Such as figure 2 As shown, the present embodiment 3 provides a computer text classification system, including:
[0063] A text preprocessing module, a text feature extraction module, a text training processing module, a classification processing module, a text type labeling module and an effect improvement module are sequentially connected.
[0064] Specifically, the text preprocessing module is adapted to remove punctuation marks and spaces in the input text, segment it into word sets, and remove meaningless words; that is, form a simplified word set.
[0065] Specifically, the text feature extraction module is adapted to generate a subset of feature words from the reduced set of words, and obtain a mapping table between feature words and the frequency of occurrence of the feature words.
[0066] Specifically, the text training processing module is suitable for processing the mapping table; that is, randomly select other texts, calculate the inverse text frequency in...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More