Data processing method and device for distributed relational database
A data processing device and data processing technology, applied in the database field, can solve the problems of low master node processing efficiency, time-consuming, high cost of data redistribution, etc., and achieve the goal of improving data processing efficiency, reducing physical load, and maximizing parallelism Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0046] The source data in the distributed relational database is distributed in the fragmented data of the first table and the fragmented data of the second table after the horizontal segmentation operation of the distribution key. The connection fields of the first table and the second table are the source data respectively In the first attribute field and the second attribute field, and neither the first attribute field nor the second attribute field is a distribution key, the distributed relational database includes a master node and multiple child nodes, wherein the first table and the second The join operation of the table is used as the original join operation.
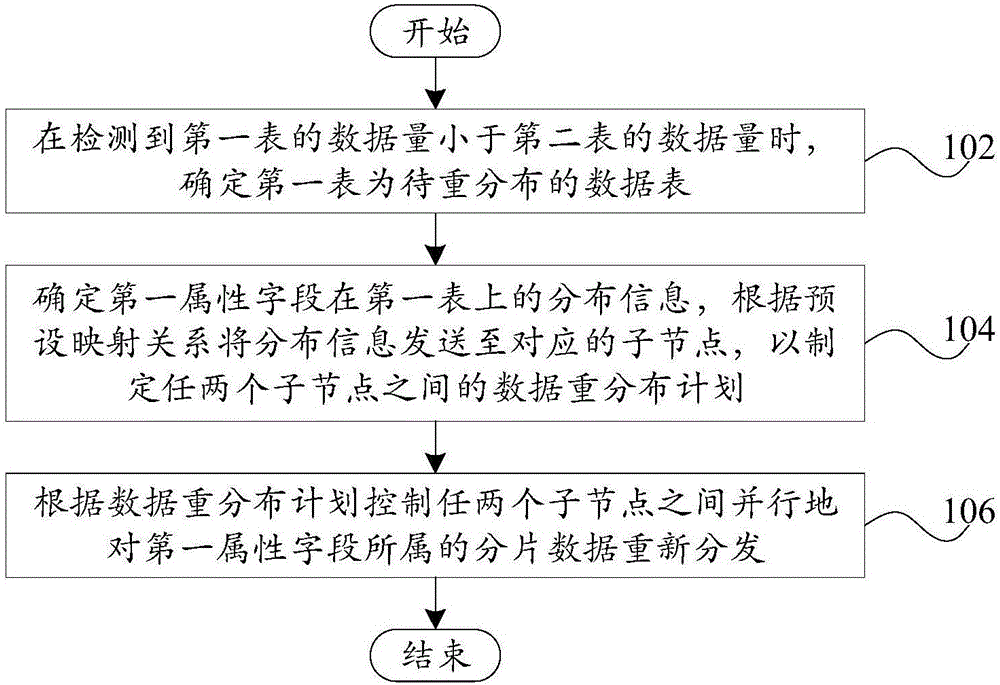
[0047] figure 1 A schematic flowchart of Embodiment 1 of the data processing method for a distributed relational database according to the present invention is shown.
[0048] Such as figure 1 As shown, the data processing method of the distributed relational database according to the embodiment of the present...
Embodiment 2
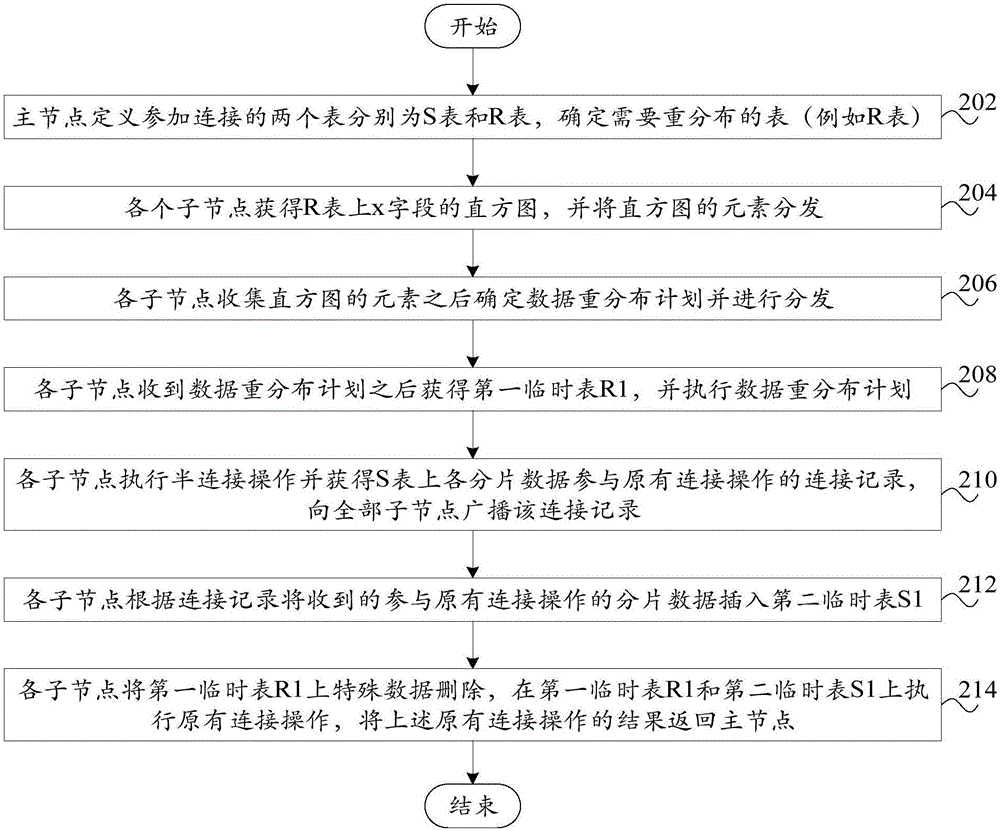
[0061] figure 2 A schematic flowchart of Embodiment 2 of the data processing method for a distributed relational database according to the present invention is shown.
[0062] Such as figure 2 As shown, the data processing method of the distributed relational database according to the embodiment of the present invention includes: step 202, the master node defines two tables participating in the connection as S table and R table respectively, and determines the table (such as R table) that needs to be redistributed ); Step 204, each sub-node obtains the histogram of the x field on the R table, and distributes the elements of the histogram; Step 206, after each sub-node receives the elements of the histogram, determines the data redistribution plan and distributes; Step 208 , each child node obtains the first temporary table R1 after receiving the data redistribution plan, and executes the data redistribution plan; step 210, each child node performs a semi-join operation and ...
Embodiment 3
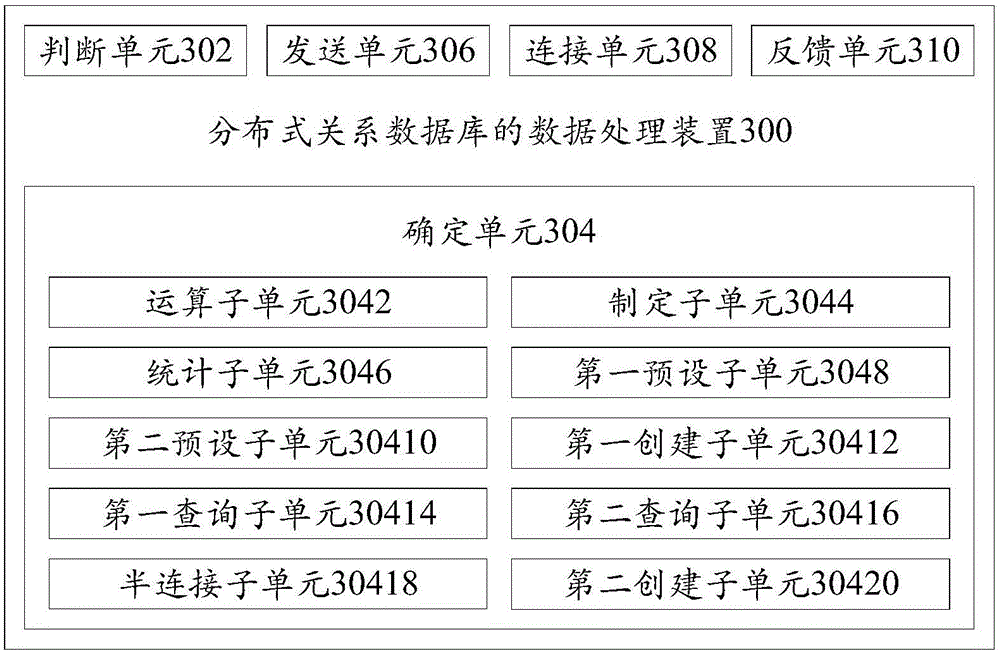
[0082] image 3 A schematic block diagram of a data processing device for a distributed relational database according to an embodiment of the present invention is shown.
[0083] The source data in the distributed relational database is distributed in the fragmented data of the first table and the fragmented data of the second table after the horizontal segmentation operation of the distribution key. The connection fields of the first table and the second table are the source data respectively In the first attribute field and the second attribute field, and neither the first attribute field nor the second attribute field is a distribution key, the distributed relational database includes a master node and multiple child nodes, wherein the first table and the second The join operation of the table is used as the original join operation.
[0084] Such as image 3 As shown, the data processing device 300 of the distributed relational database according to the embodiment of the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com