

A method and device for creating audio abstract text based on speech recognition
A speech recognition and audio technology, used in speech recognition, speech analysis, instruments, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
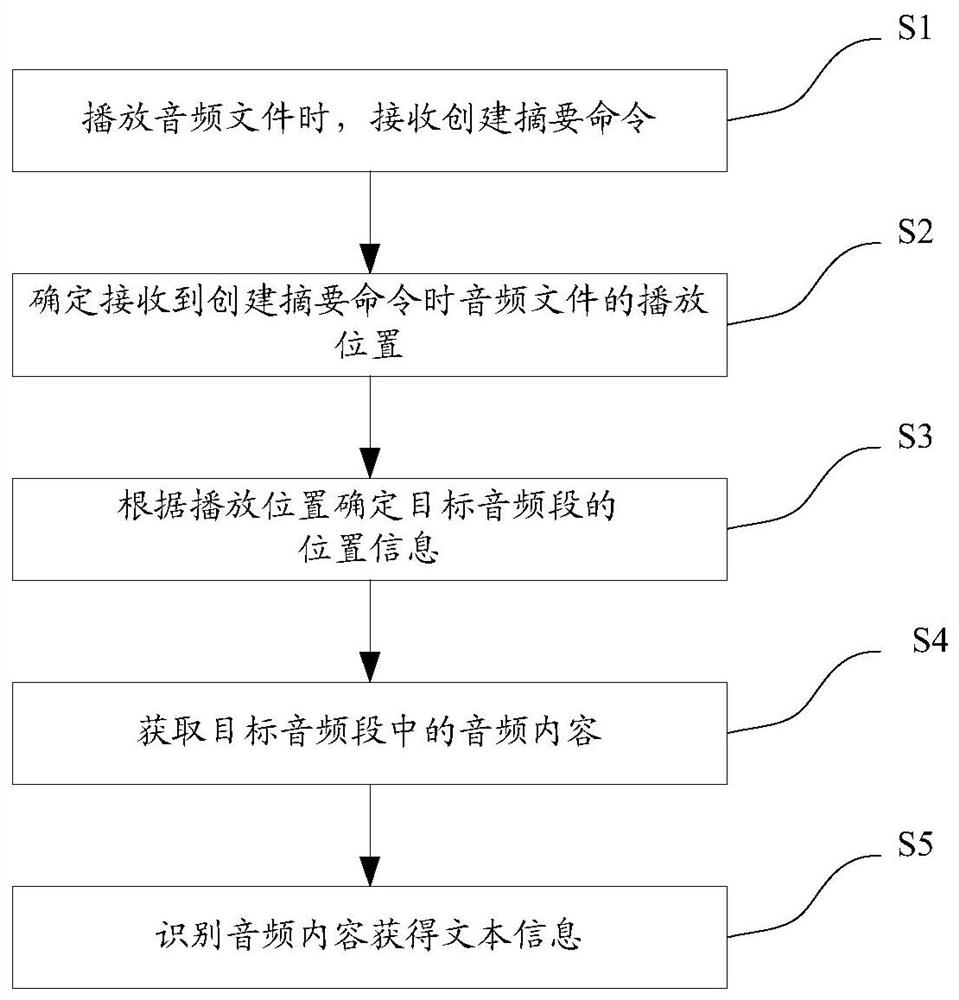
[0057]The first embodiment of the present invention is described for the case of creating an audio summary once, please refer to figure 2 . The so-called one-time creation of an audio summary means that the summary creation command is only received once during the playback of an audio file.
[0058] First, there is a shortcut for the user to issue a create summary command for the audio file being played. The shortcut here includes using a shortcut key or a combination of multiple shortcut keys. The command to create a summary may be a command issued by a hardware component of the device, for example, a signal issued when the volume down key and a power key are pressed simultaneously on a mobile phone, or a signal issued when a certain key is pressed and held. Another example is the touch screen signal received by the playback software when playing audio, such as the signal of double-clicking the screen, the signal of drawing a preset graphic on the screen, and so on. Creat...
no. 2 example
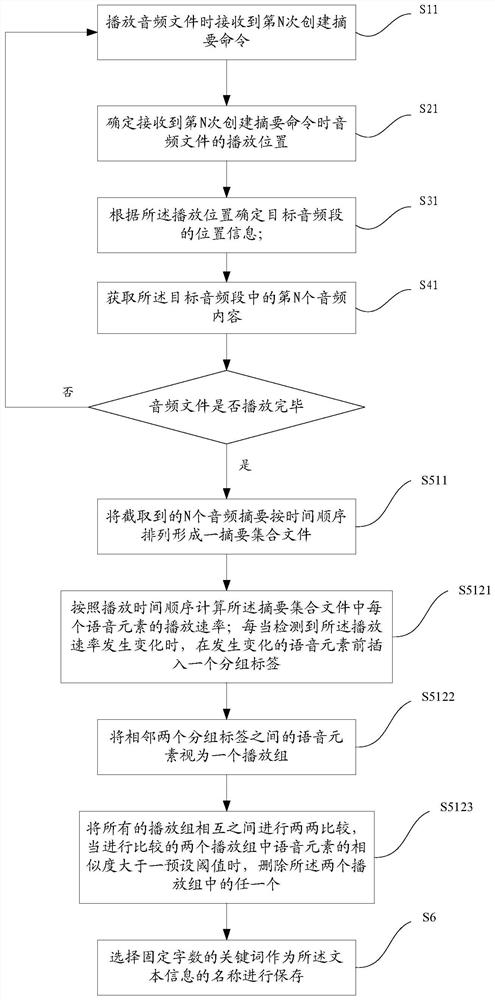
[0064] The second embodiment of the present invention is described for the situation of creating audio summaries multiple times, please refer to figure 2 . The multiple creation of audio abstracts in this embodiment is relative to the single creation of audio abstracts in the first embodiment. Because in the process of actually listening to the audio file, the audience may not only be interested in a piece of content, but hear different exciting parts continuously. At this time, it is necessary to use the method of creating audio summaries multiple times to meet the audience's demand for simultaneous creation of summaries for multiple pieces of content. The specific content includes the following steps:
[0065] First, the first creation summary command is still received when playing an audio file;
[0066] Secondly, determine the playback position of the audio file when receiving the summary command for the first time; determine the position information of the target audi...
no. 3 example
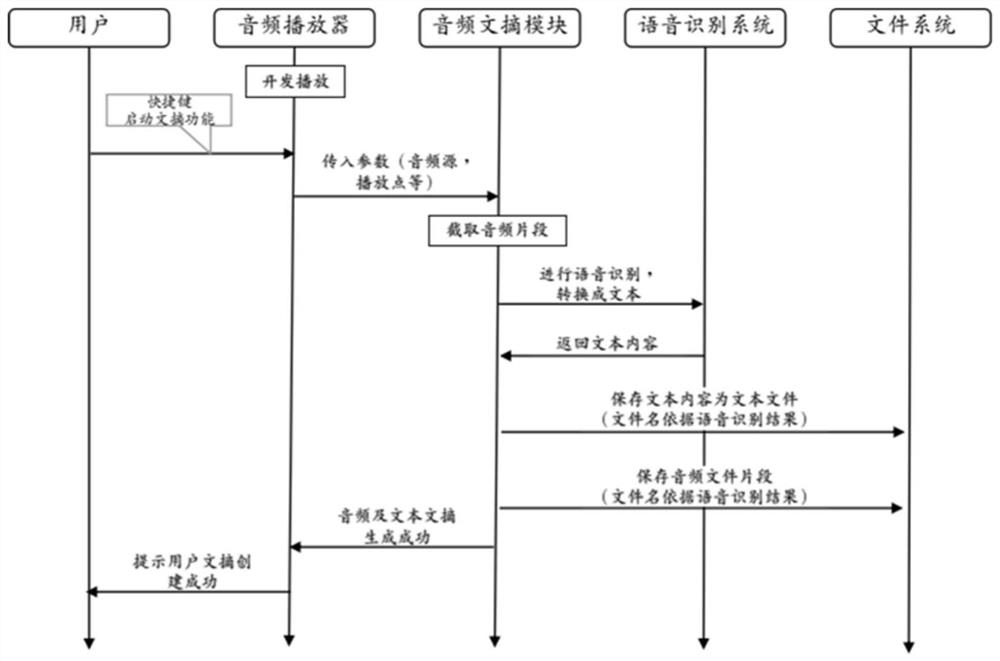
[0080] The present invention also provides a device for creating audio summary text based on speech recognition, such as Figure 4 ,include:
[0081] Command receiving module: used to receive the creation summary command when playing the audio file;
[0082] Playing position determination module: used to determine the playing position of the audio file when receiving the creation summary command;
[0083] Audio segment position determination module: connected to the playback position determination module, used to determine the position information of the target audio segment according to the playback position;
[0084] Obtaining module: used to obtain the audio content in the target audio segment;
[0085] Recognition module: used to recognize audio content to obtain text information.
[0086] Wherein, the method for determining the location information of the target audio segment by the audio segment position determination module includes any one of the following:
[0087...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More