

Method for improving query efficiency of Spark SQL
A technology for query efficiency and intermediate data, which is applied to improve the query efficiency of SparkSQL, and can solve the problem of high disk I/O overhead
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

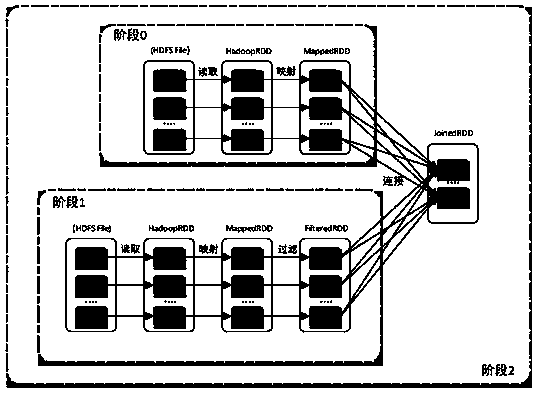
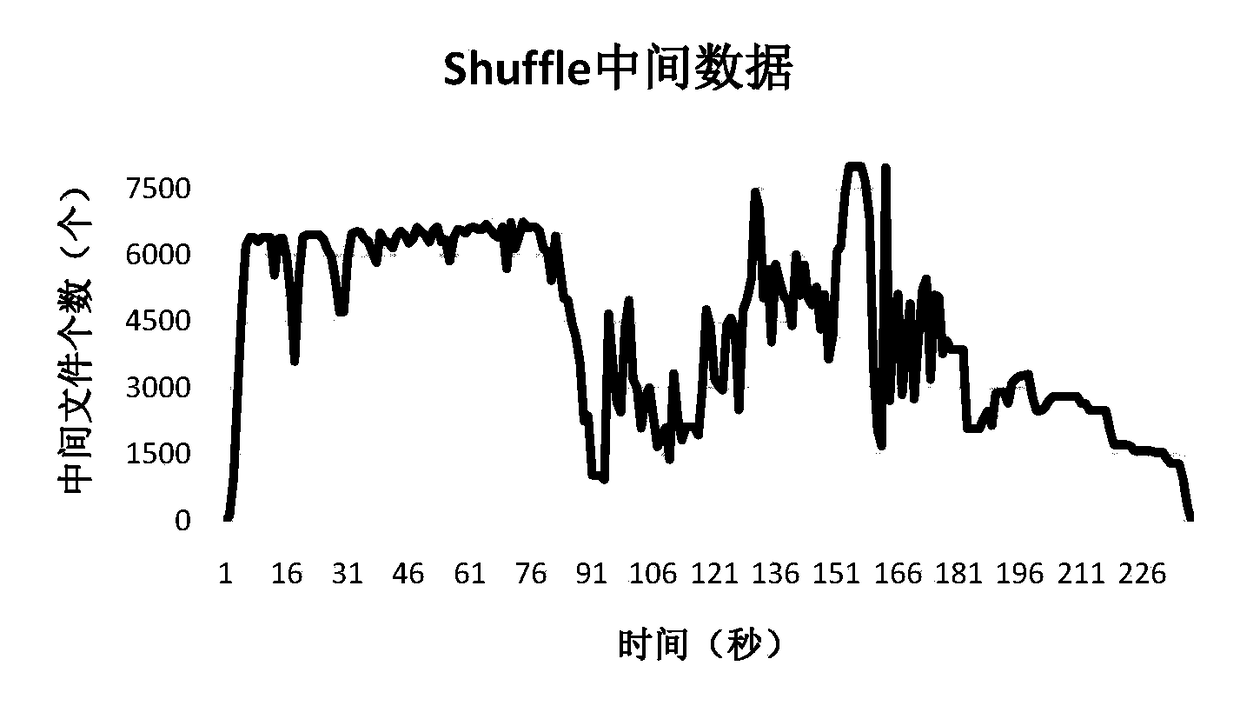
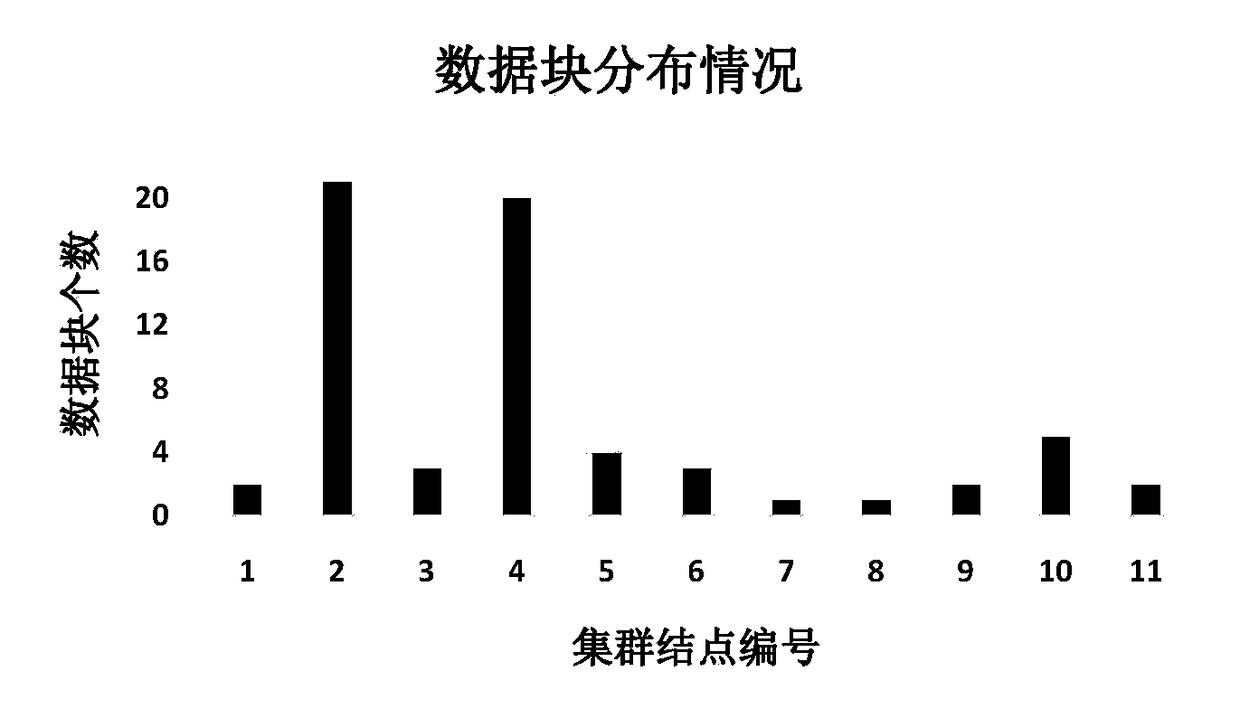
Examples
Embodiment Construction
[0040] The present invention will be further illustrated below in conjunction with specific embodiments, and it should be understood that the following specific embodiments are only used to illustrate the present invention and are not intended to limit the scope of the present invention.
[0041] A method for improving the query efficiency of Spark SQL, the method comprises the steps:
[0042] Step S1: Build a query pre-analysis module, calculate the size of the intermediate data generated by Shuffle through the estimation model, and calculate the total size of the intermediate data cache layer used to cache the intermediate data;
[0043] Step S2: According to the total size of the intermediate data cache layer calculated in step 1, combined with the distribution of input data of each node in the cluster, set a reasonable memory space size for each node through the cache layer allocation module.
[0044]Further, the specific method for calculating the size of the intermediate...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More