

Large-scale data parallel query method based on subgraph matching
A large-scale data and query method technology, applied in the direction of electronic digital data processing, special data processing applications, digital data information retrieval, etc., can solve the problems that data query solutions cannot solve data query problems quickly and accurately
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
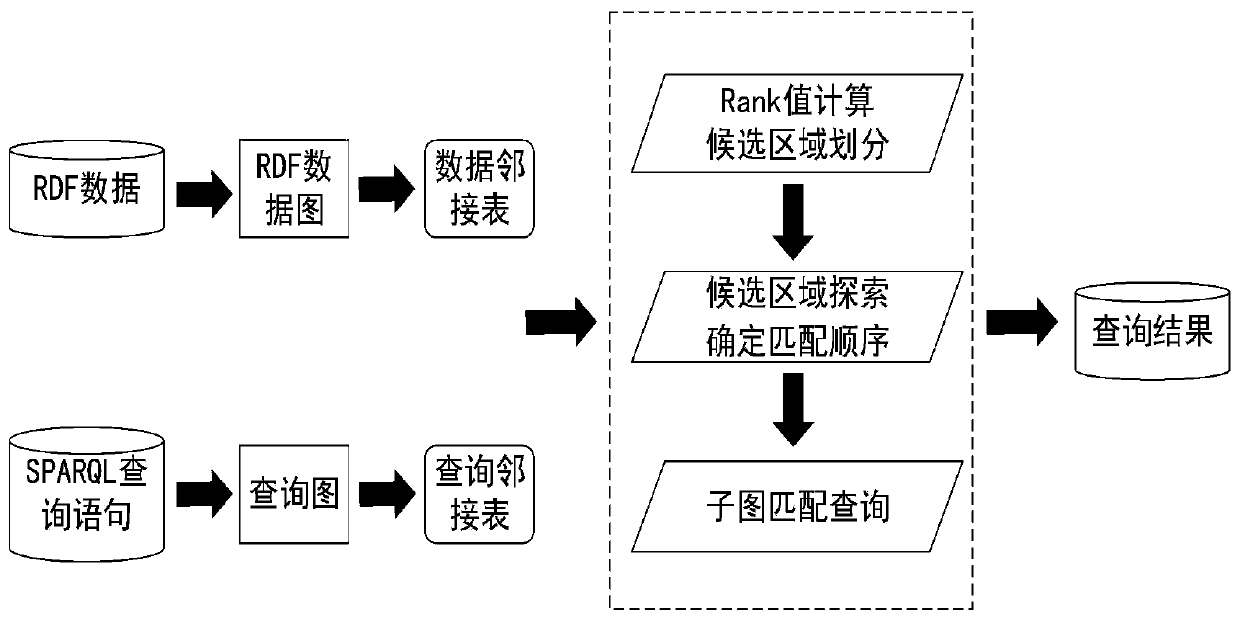
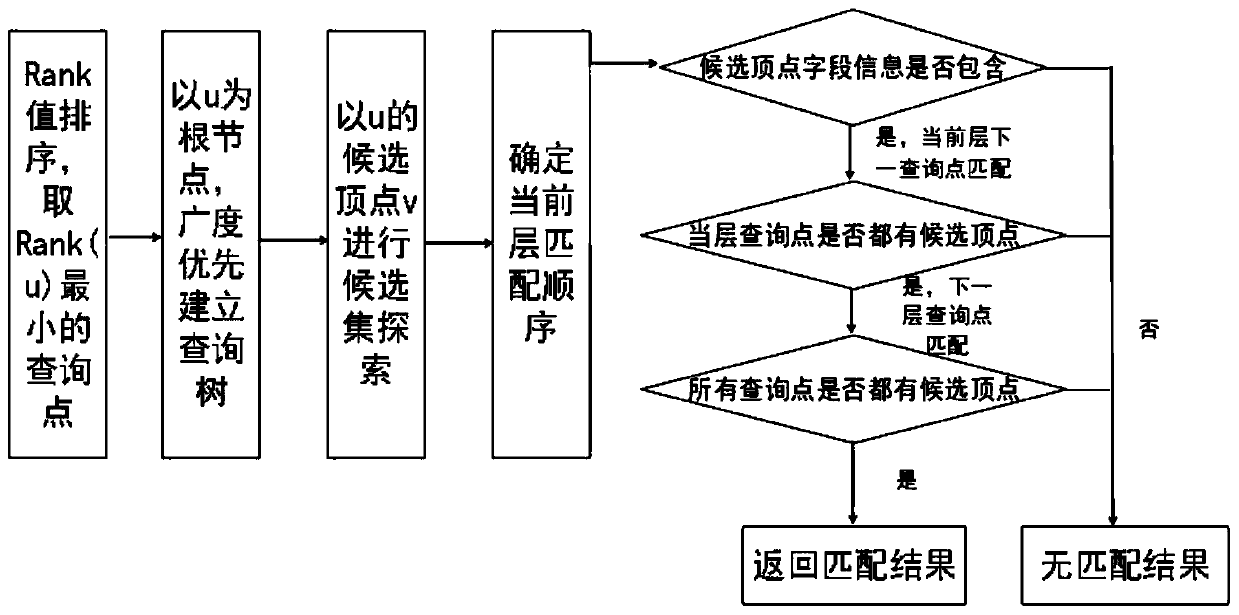
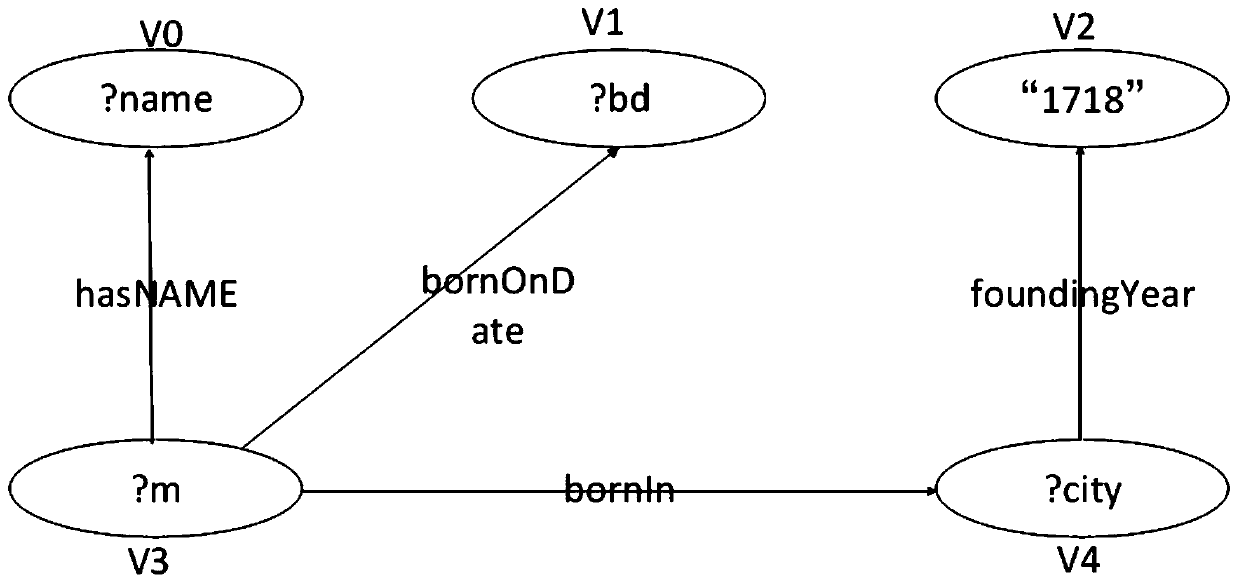
[0019] In order to make the purpose, characteristics and advantages of the present invention more obvious and easy to understand, the present invention will be further described in the following in combination with the basic theory and formula drawings, according to the sequence of basic principles, macro flow and specific steps.
[0020] Before performing the specific query process, it is necessary to establish an adjacency table for the RDF data graph. The specific format of the adjacency table is as follows:
[0021]
[0022]
[0023] In the table, each vertex u is represented by an adjacency list [uid, ulabel, adjlist], where uid is the vertex ID, uLabel is the attribute corresponding to the vertex, adjList is the edge attribute of the point and the adjacent vertex attributes connected by the edge In general, adjList(u)={(ei.eLabel,ei.nLabel)}, where ei is the edge adjacent to point u, eLabel is the edge label attribute of ei, and nLabel is connected by the edge ei A...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More