

Voice synthesis method and device and electronic equipment
A technology of speech synthesis and speech library, applied in speech synthesis, speech analysis, instruments, etc., can solve the problems of strong sound quality, poor stability outside the set, loss of sound quality and tone details, etc., to improve the effect and increase efficiency Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0067] figure 1 It is a flowchart of steps of a speech synthesis method provided by an embodiment of the present invention.
[0068] refer to figure 1 As shown, the speech synthesis method provided by this embodiment is applied to electronic devices such as electronic computers or speech synthesis equipment, and specifically includes the following steps:
[0069] S1. Perform text analysis on the input text.
[0070] When the user directly inputs or other electronic equipment inputs the corresponding text, text analysis is performed on the input text, and the target primitive sequence and corresponding context information are obtained from it. The target primitive sequence here includes multiple target primitives.
[0071] S2. Utilize the traditional model decision tree to determine the subcategory number and the corresponding Gaussian distribution model respectively described in the voice selection target model of the contextual information in the speech bank.
[0072] The...
Embodiment 2
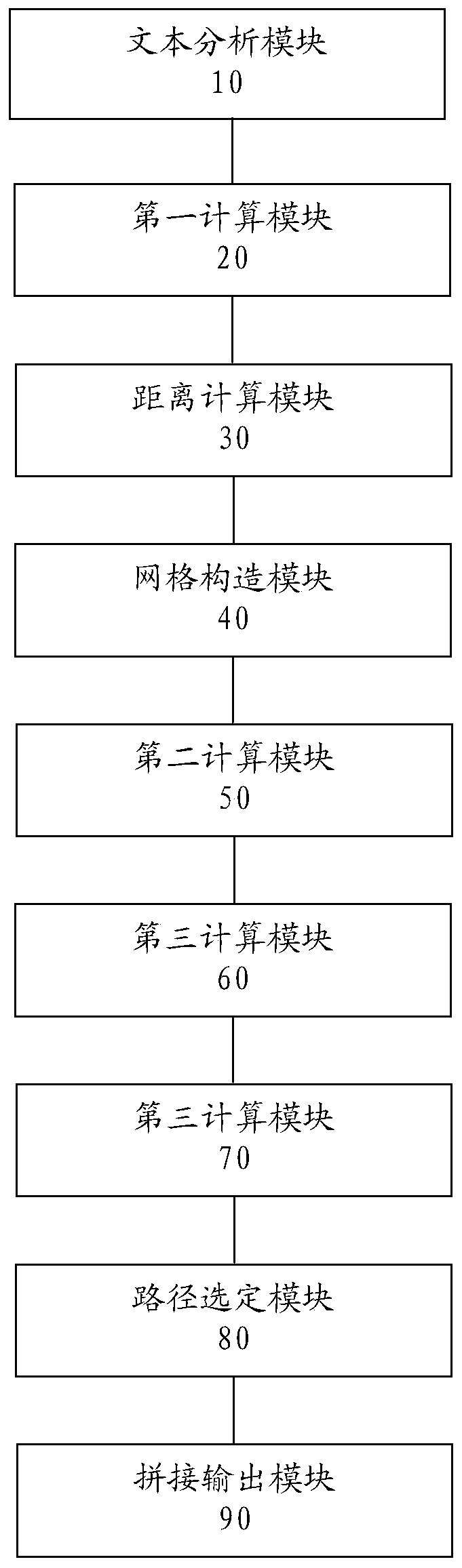
[0150] figure 2 It is a structural block diagram of a speech synthesis device provided by an embodiment of the present invention.
[0151] refer to figure 2 As shown, the speech synthesis device provided by this embodiment is applied to electronic equipment such as electronic computers or speech synthesis equipment, and specifically includes a text analysis module 10, a first calculation module 20, a distance calculation module 30, a grid construction module 40, a second Calculation module 50 , third calculation module 60 , fourth calculation module 70 , path selection module 80 and splicing output module 90 .
[0152] The text analysis module is used to perform text analysis on the input text.
[0153] When the user directly inputs or other electronic equipment inputs the corresponding text, text analysis is performed on the input text, and the target primitive sequence and corresponding context information are obtained from it. The target primitive sequence here include...
Embodiment 3
[0186] This embodiment provides an electronic device, such as a speech synthesis device, an electronic computer or a mobile terminal, etc., which is provided with the speech synthesis device provided in the previous embodiment. The device is used to perform text analysis on the input text to obtain the target primitive sequence and the corresponding context information; for the context information, the traditional model decision tree is used to determine the context information in the voice selection target model of the speech library. The subclass number and the corresponding Gaussian distribution model are used to obtain the corresponding pre-selection results; the pre-selection results are used to form a column for each target primitive in turn, and finally the target primitive sequence forms a set of candidate grids; the context information is input into the deep learning model to obtain the acoustic parameter envelope, primitive duration, and boundary frame acoustic parame...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More