Railway accident cause analysis method based on word extension LDA
A technology of accident causes and analysis methods, applied in the fields of resources, instruments, electrical and digital data processing, etc., can solve problems such as the decline of expert judgment ability and the influence of subjective accident analysis results, and achieve the effect of deepening understanding
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
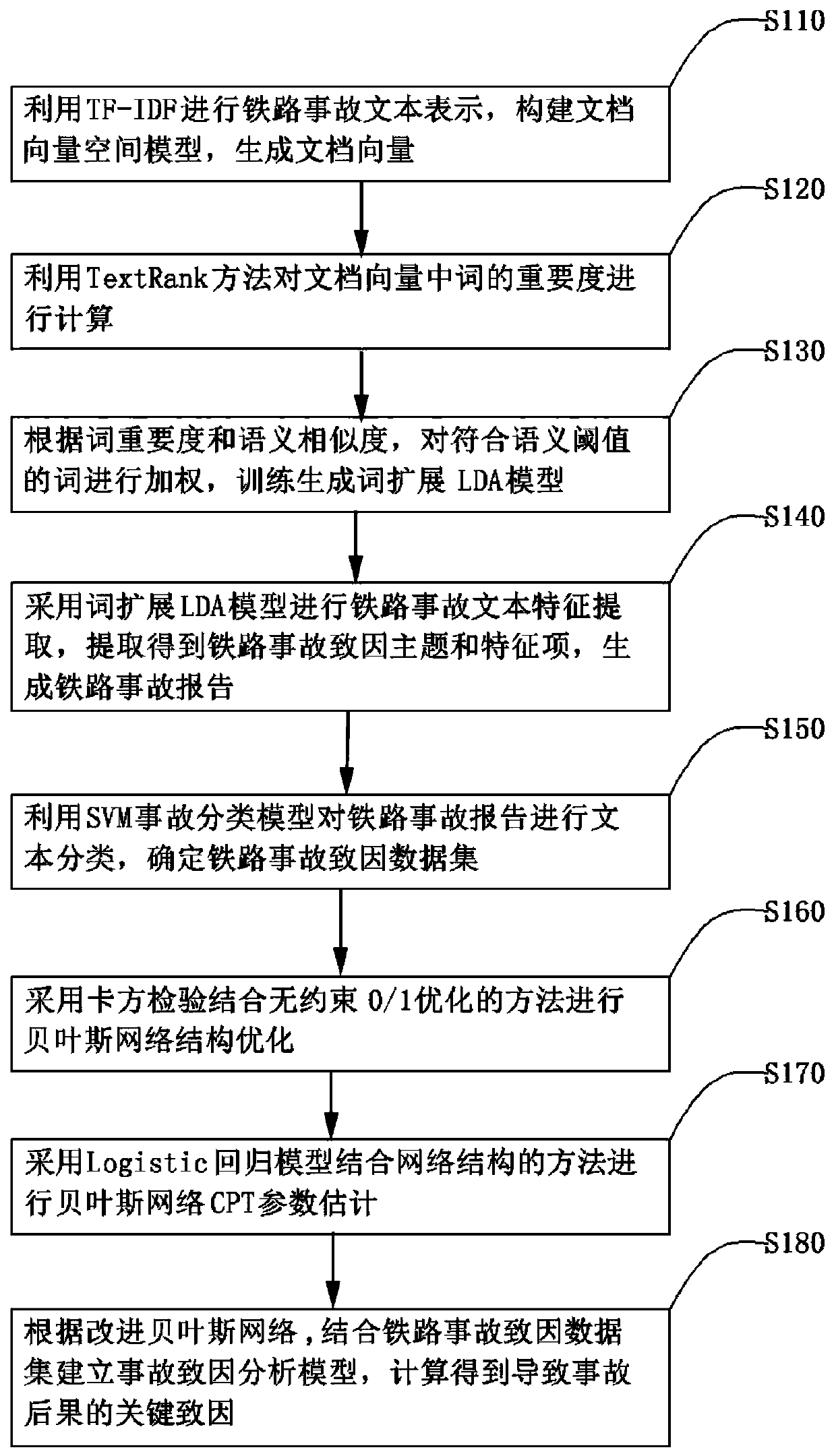
[0046] like figure 1 As shown, the first embodiment of the present invention provides a method for analyzing the causes of railway accidents, and the method includes the following steps:
[0047] Step S110: use TF-IDF to represent the text of the railway accident, build a document vector space model, and generate a document vector;
[0048] Step S120: using the TextRank method to calculate the importance of words in the railway accident text;
[0049] Step S130: according to the word importance and semantic similarity, weight the words that meet the semantic threshold, and train the generated word extended LDA model;
[0050] Step S140: using the word extension LDA model to extract the text features of the railway accident, and extracting the theme and feature items of the cause of the railway accident;
[0051] Step S150: Use the SVM accident classification model to classify the text of the railway accident report, and determine the railway accident cause data set;
[0052...
Embodiment 2
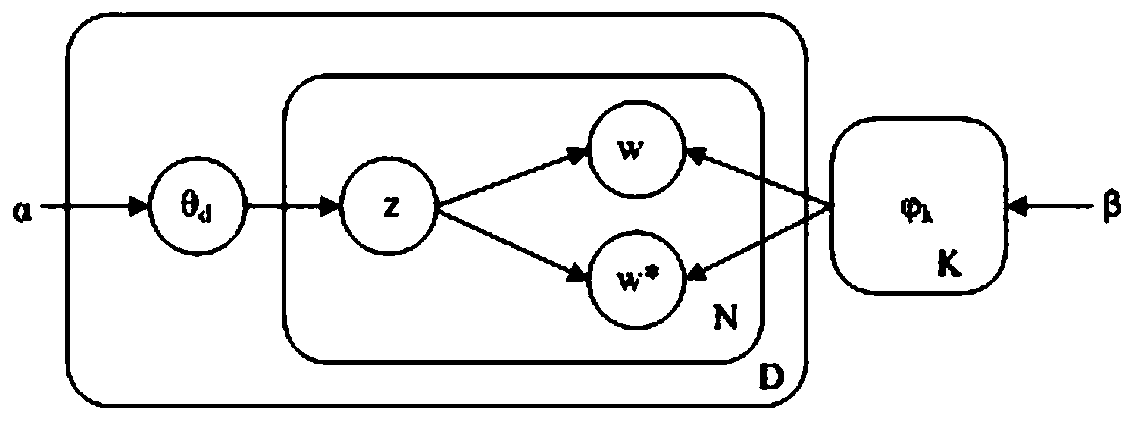
[0064] like figure 2 As shown, the second embodiment of the present invention provides a word extension LDA topic model construction method based on word importance and semantic similarity, and the method includes the following process steps:
[0065] Step 1.1. Use the TextRank method to calculate the importance of words in the document
[0066] Specifically, the given accident text is divided into complete sentences, word segmentation is performed for each sentence, and stop words are removed, each sentence is represented as a set of phrases, a word graph is constructed, and then a co-occurrence relationship is used to construct any The edge between two words, only when two words co-occur in a fixed-length window, there is an edge between them, the importance of all words is initialized, and the importance of each word is calculated through multiple iterations, by setting The maximum number of iterations is used to control the calculation, and the final iteration result is ...
Embodiment 3
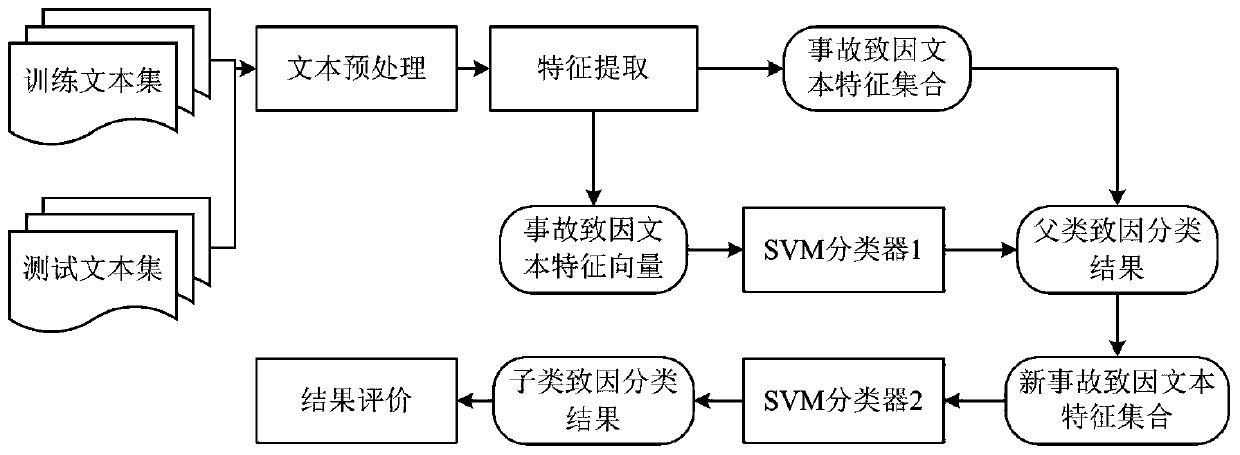
[0076] like image 3 As shown, the third embodiment of the present invention provides a text classification method based on two-level accident causes using the SVM accident classification model, and the method includes the following steps:
[0077] Step 2.1. Build an improved HFACS-RAs model.
[0078] Using the word-expanded LDA topic model generated by the training in Example 2 to extract the topic features of the accident text, and each topic selects the top eight topic words in the frequency ranking as the accident causative feature items to form the accident causation feature space; from the meaning of the topic words The human factor and organizational classification in the current accident can be identified. Based on the content extracted from the accident text features, an improved HFACS-RAs model is designed on the basis of the HFACS-RAs model, such as Figure 4 As shown, "preconditions for unsafe behavior" are further divided into "personal conditions for unsafe beha...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



