

Data acquisition system and method based on scrapy crawler framework
A data acquisition system and crawler technology, which is applied in the direction of network data indexing, network data retrieval, and other database retrieval, can solve the problems of slow crawling speed and exhaustion of single-machine memory, so as to ensure reliability, improve crawling breadth, Improve the effect of crawling stability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0023] The specific implementation manners of the present invention will be further described in detail below in conjunction with the accompanying drawings.
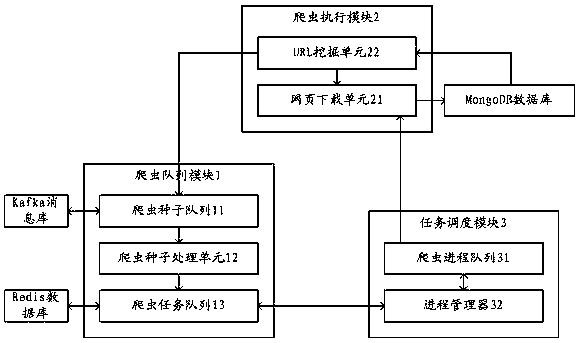
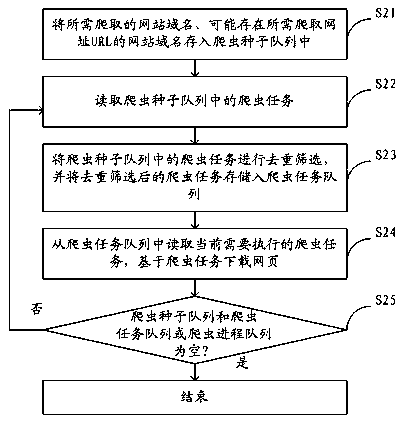
[0024] The data acquisition system based on the scrapy crawler framework proposed by the present invention, such as figure 1 As shown, it includes a crawler queue module 1, a crawler execution module 2 and a task scheduling module 3; wherein, the crawler queue module 1 includes a crawler seed queue 11, a crawler seed processing unit 12 and a crawler task queue 13; the crawler execution module 2 includes a webpage download unit 21 and a URL mining unit 22; the task scheduling module 3 includes a crawler process queue 31 and a process manager 32.
[0025] The crawler seed queue 11 is used to store crawler tasks, including but not limited to crawler tasks sent by users and new crawler tasks submitted by the crawler execution module 2; the crawler seed processing unit 12 is used to deduplicate the crawler tasks in the crawle...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More