

A Text-to-Video Cross-Modal Retrieval Method Based on Multi-Level Coding
A cross-modal, text technology, applied in the field of video cross-modal retrieval, can solve the problems of information loss, difficulty and low retrieval efficiency, and achieve the effect of improving performance and efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0038] In order to make the above objects, features and advantages of the present invention more clearly understood, the specific embodiments of the present invention will be described in detail below with reference to the accompanying drawings.
[0039] Many specific details are set forth in the following description to facilitate a full understanding of the present invention, but the present invention can also be implemented in other ways different from those described herein, and those skilled in the art can do so without departing from the connotation of the present invention. Similar promotion, therefore, the present invention is not limited by the specific embodiments disclosed below.
[0040] The present invention proposes a text-to-video cross-modal retrieval method based on multi-level coding, including:
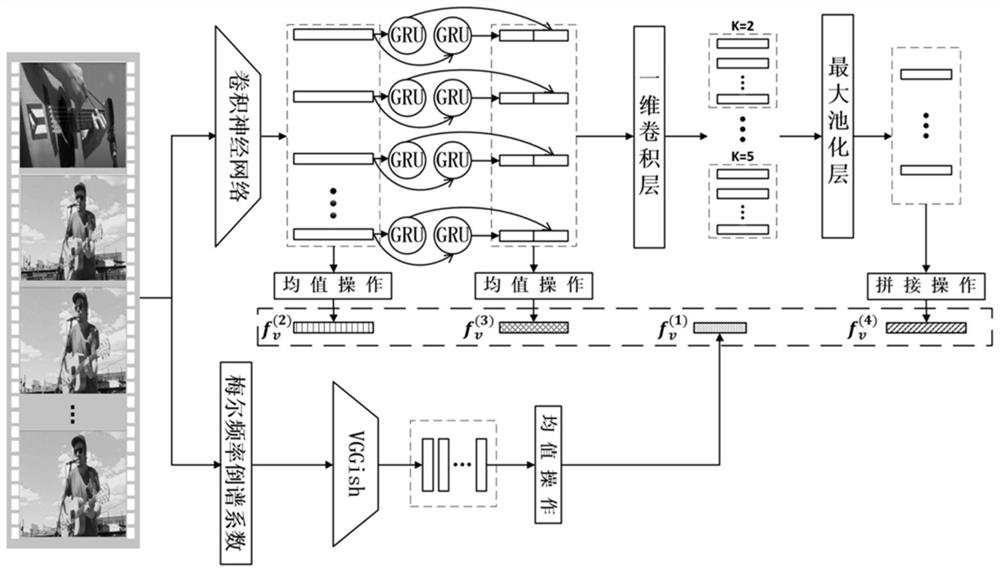
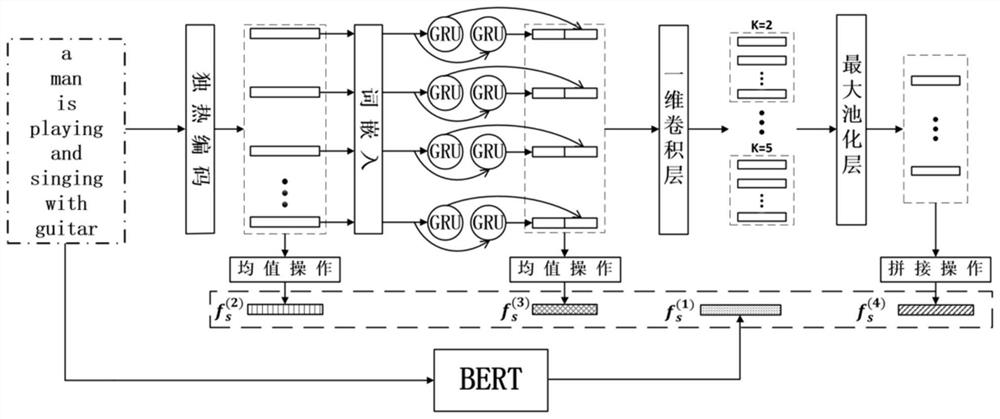
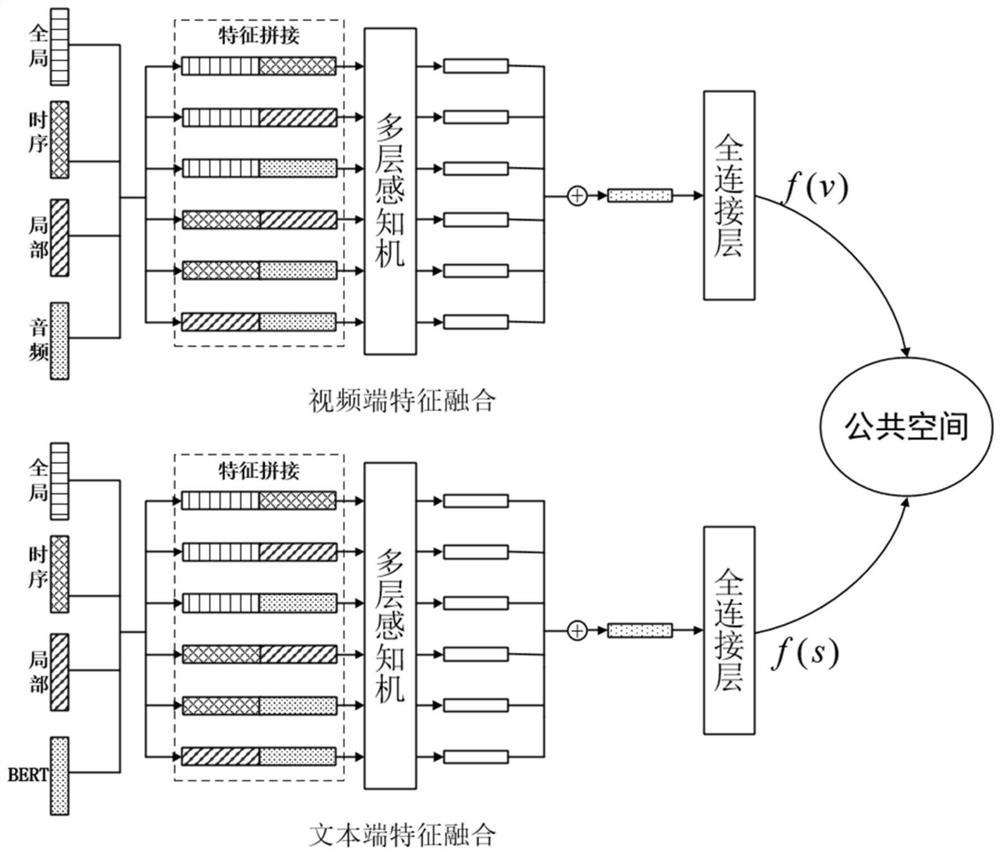
[0041] (1) Using different feature extraction methods to extract the features of the two modalities of video and text, respectively.
[0042](1-1) For a given vide...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More