

Resume information extraction method based on cascading sequence annotation
A technology of sequence labeling and information extraction, which is applied to instruments, text database query, unstructured text data retrieval, etc. It can solve the problem of not considering the structure of resume text blocks, and achieve the effect of solving the problem of confusion.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
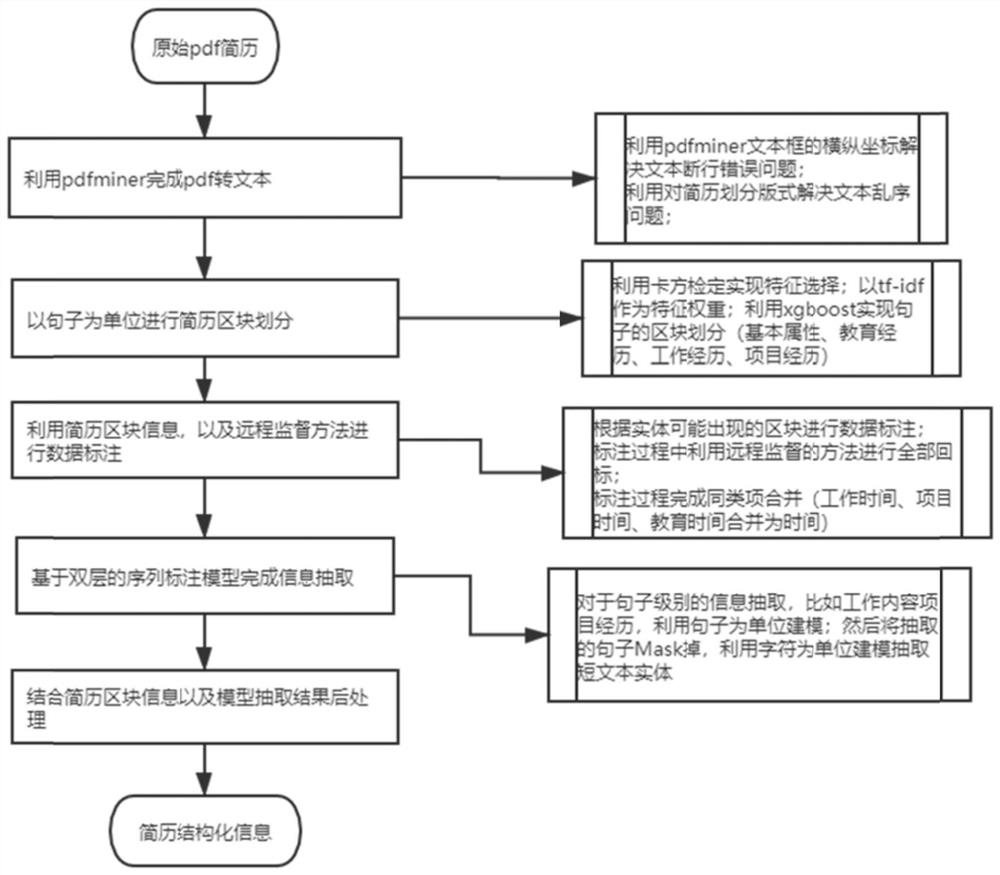
[0051] Such as figure 1 As shown, the present invention provides a method for extracting resume information based on stacked sequence annotation, comprising the following steps:
[0052] Step 1, use pdfminer to analyze the resume file in pdf format, and parse the rich-text resume into a text representation in common format;
[0053] Step 2, data labeling during training: use remote supervised data to back-label and merge similar items during the labeling process;
[0054] Step 3, divide the resume information into blocks: divide the resume into 4 blocks, and train the classifier to divide the text into blocks;
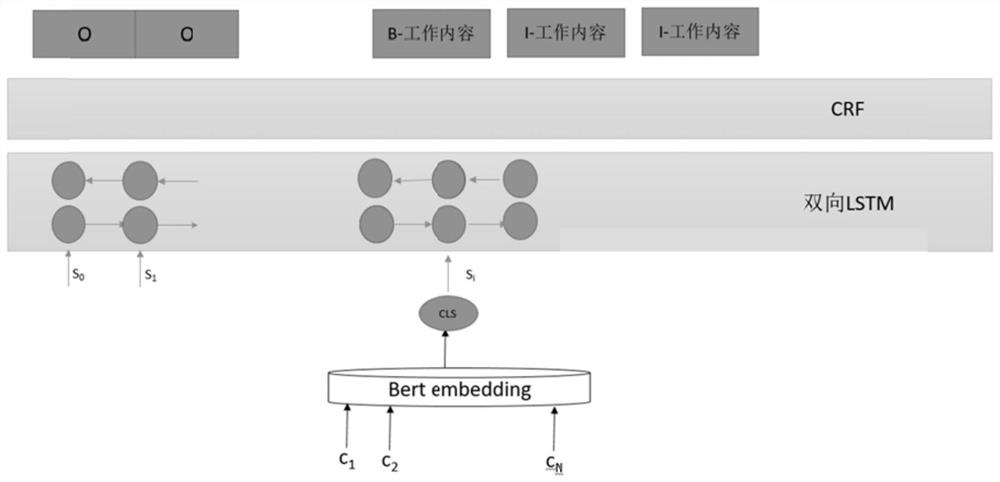
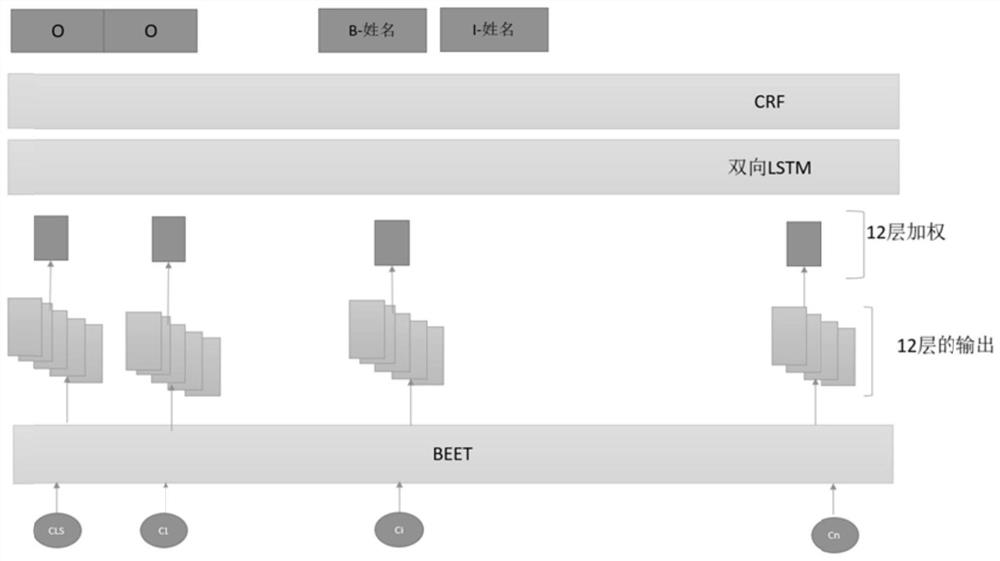
[0055] Step 4, using the two-layer sequence labeling model to realize information extraction at the sentence level and short text segment level.
[0056] Step 1 includes:
[0057] PDF is a kind of rich text, which needs to be parsed into ordinary plain text format first. The parsing process will involve issues of column division, section division and line breaking. ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More