

Picture text cross-modal retrieval method based on self-supervised adversarial
A cross-modal, text technology, applied in the field of image and text cross-modal retrieval based on self-supervised confrontation, can solve the problem of affecting the cross-modal retrieval effect of icon text, the failure of samples to be successfully discriminated by the discriminator, and hindering cross-modal retrieval, etc. question
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

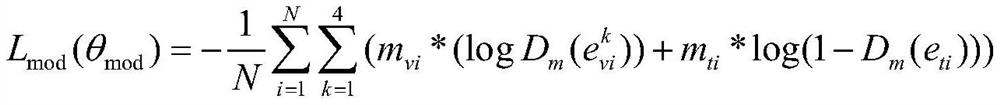
Examples
Embodiment Construction
[0050] Specific embodiments of the present invention will be described below in conjunction with the accompanying drawings, so that those skilled in the art can better understand the present invention. It should be noted that in the following description, when detailed descriptions of known functions and designs may dilute the main content of the present invention, these descriptions will be omitted here.
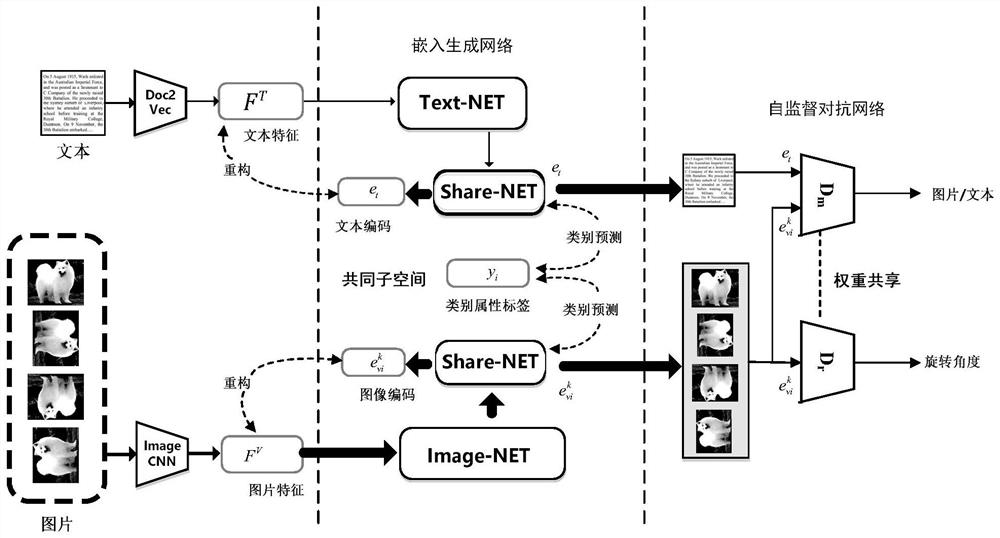
[0051] figure 1 It is a flow chart of a specific embodiment of the self-supervised confrontation-based image-text cross-modal retrieval method of the present invention.
[0052] In this example, if figure 1 As shown, the present invention is based on self-supervised confrontation image text cross-modal retrieval method, it is characterized in that, comprises the following steps:
[0053] Step S1: Build the Embedding Generative Network
[0054] In this example, if figure 2 As shown, two independent single-layer feedforward neural networks are constructed as image networ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More