Multi-objective robot control method based on dynamic model and post-event experience replay
A dynamic model and control method technology, applied in the direction of a specific mathematical model, calculation model, program-controlled manipulator, etc., can solve the problems of accelerated robot task training, large offline deviation, poor generalization, etc., to improve data utilization efficiency. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

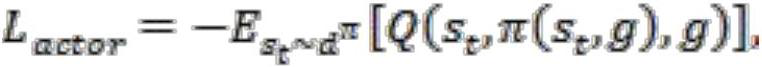
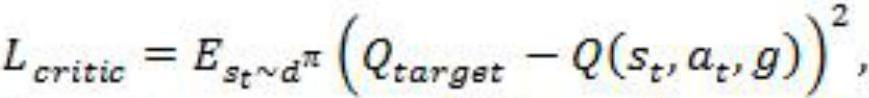
Examples
Embodiment Construction
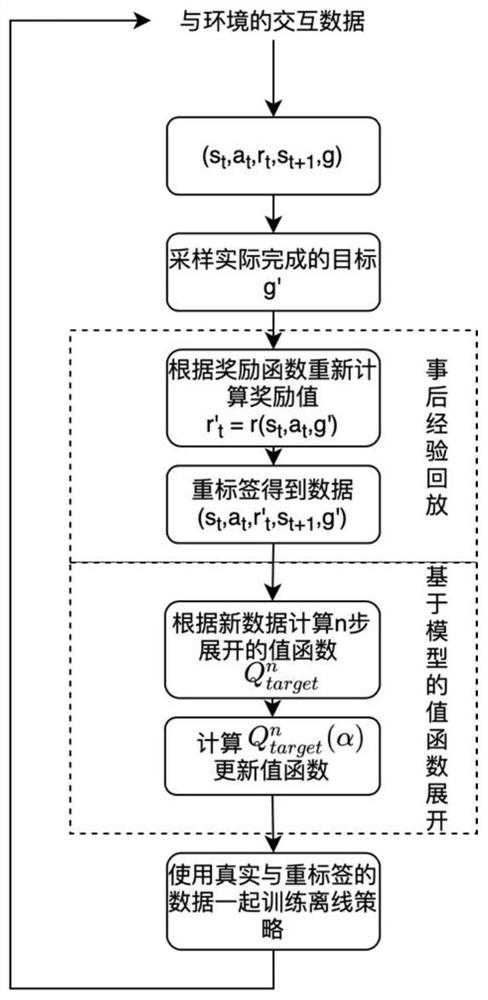
[0043] Such as figure 1 As shown, a multi-objective robot control method based on dynamic model and post-event experience playback, the specific method is as follows:
[0044] (1) Setting multi-objective reinforcement learning parameters;
[0045] (2) Under the parameter setting of multi-objective reinforcement learning, the loss function L of the deterministic policy gradient algorithm Actor and Critic is obtained actor and L critic ;
[0046] (3) Establish a dynamic model, based on the dynamic model and single-step value function estimation and multi-step value function expansion to accelerate multi-objective reinforcement learning training;
[0047] (4) Using post-event experience replay technology, in multi-objective reinforcement learning, replace the failed-experienced goals with the actually completed goals.
[0048] The details of the multi-objective reinforcement learning parameters are as follows:
[0049] Reinforcement learning is expressed as a Markov decision p...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More