

A method for multimodal video question answering using frame-subtitle self-supervision
A multi-modal, subtitle technology, applied in the field of video question answering, can solve the problems of expensive time tags, ignoring the correspondence between frames and subtitles, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


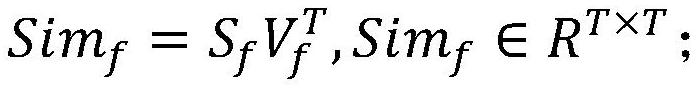
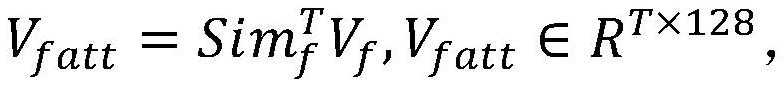
Examples
Embodiment Construction
[0071] The technical solutions in the embodiments of the present invention will be clearly and completely described below with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the embodiments of the present invention, rather than all the embodiments. The following description of at least one exemplary embodiment is merely illustrative in nature and is in no way intended to limit the invention, its application, or uses. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
[0072] An embodiment of the present invention proposes a method for multi-modal video question and answer using frame-subtitle self-supervision, refer to figure 1 shown, including the following steps:
[0073] S1: For the input video, question and answer text, and...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More