Audio annotation model training and audio annotation method and device
A technology for labeling models and training methods, applied in audio data retrieval, audio data query, special data processing applications, etc., can solve problems such as insufficient accuracy and limitations, and achieve the effect of simplifying training steps and improving training efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

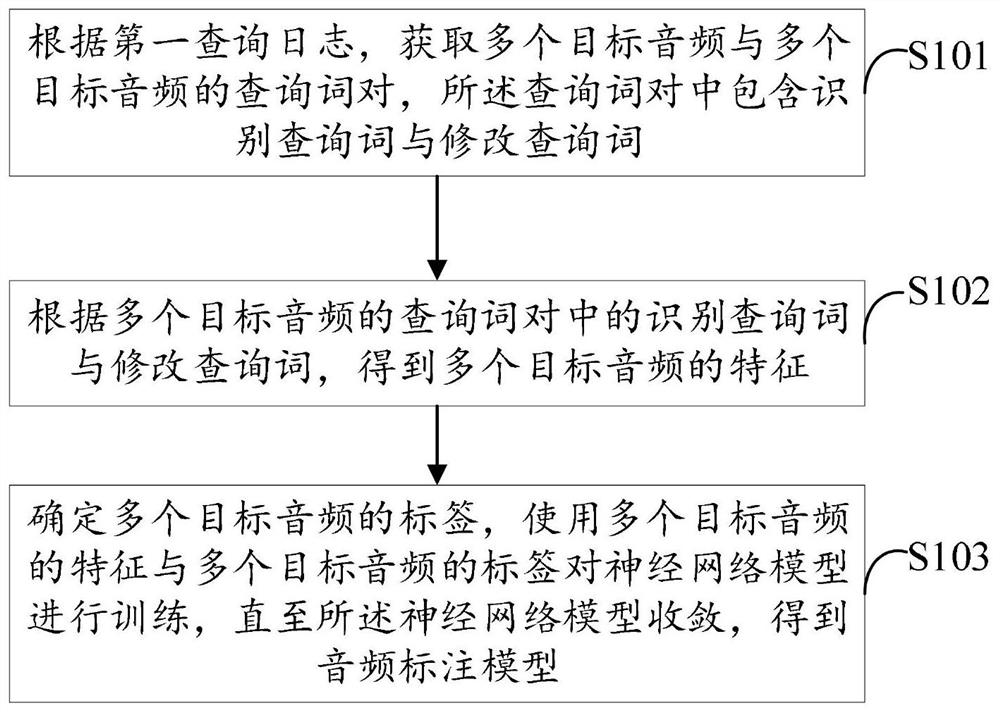

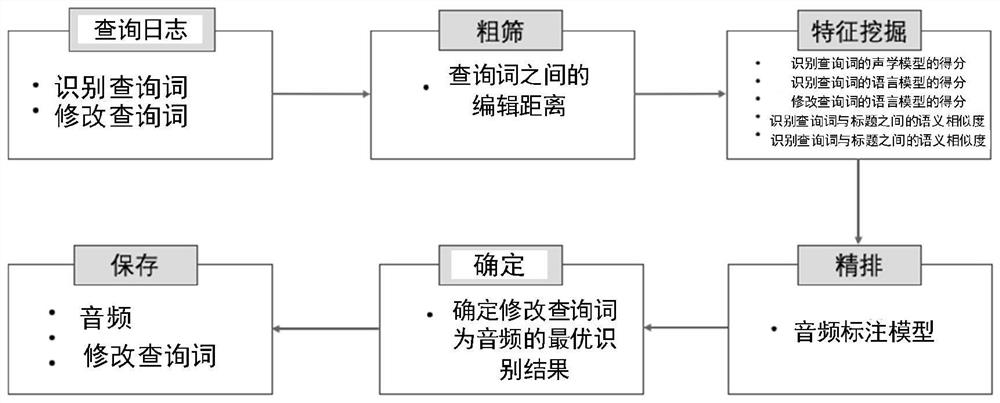
Examples
Embodiment Construction
[0019] Exemplary embodiments of the present disclosure are described below in conjunction with the accompanying drawings, which include various details of the embodiments of the present disclosure to facilitate understanding, and they should be regarded as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the disclosure. Also, descriptions of well-known functions and constructions are omitted in the following description for clarity and conciseness.
[0020] The traditional speech recognition model mainly includes three parts: decoder, acoustic model and language model. For the audio input by the user, the decoder combines the acoustic model features and language model features to expand the possible recognition paths in the decoding space, and finally selects the path with the highest feature scoring result as the f...
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap