

Researcher pre-training method based on KL regularization under open domain questions and answers
A pre-training and questioning technology, applied in the field of conversational open-domain question answering, can solve problems such as difficulty in improving training effect, large semantic difference between positive and negative samples, and large content gap, so as to improve semantic understanding ability, improve training effect, and improve stability. sexual effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
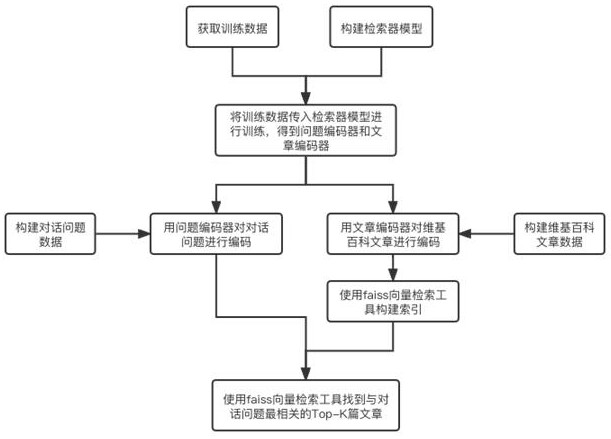
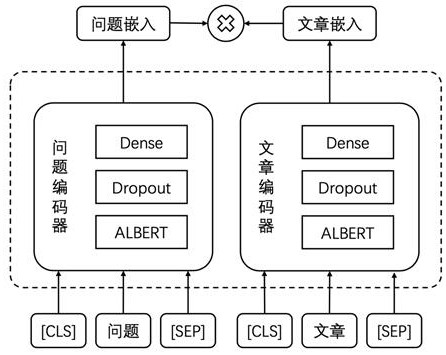
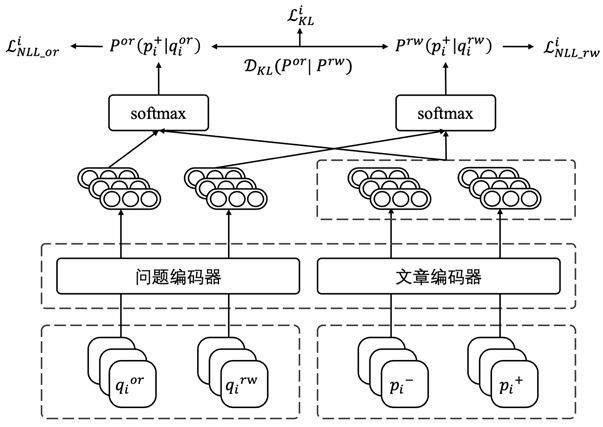
[0024] In order to clarify the technical solutions and working principles of the present invention, the embodiments disclosed in the present invention will be further described in detail below with reference to the accompanying drawings. This embodiment provides a retrieval pre-training method based on KL regularization under open domain question answering, such as figure 1 As shown, the method mainly includes the following steps:
[0025] Step 1, build training data:
[0026] Get the current question q from the OR-QuAC training dataset c and historical question and answer pairs Take the size of the historical dialogue window as w, and take the splicing of the question and the answer as the question, denoted as
[0027] q or =[CLS]q 1 [SEP]a 1 [SEP]q c-w [SEP]a c-w [SEP]…[SEP]q c-1 [SEP]a c-1 [SEP]q c [SEP].
[0028] A rewrite of the current question q rw is provided by the CANARD dataset, which replaces some demonstrative pronouns in the current problem with sub...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More