

Method for synthesizing pronunciation based on rhythm model and parameter selecting voice
A prosody and parameter technology, applied in the field of speech synthesis, can solve the problems of reducing naturalness of speech, not considering acoustic parameters, and mismatching sound length, etc., to achieve the effect of improving naturalness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
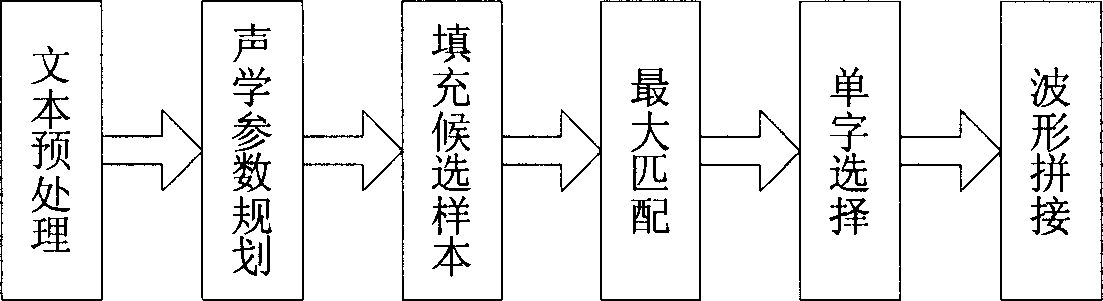
[0022] Before the specific speech synthesis, first establish the following resource base:
[0023] Large-scale recording sound library: speech waveform data, the starting position of each syllable in the speech waveform and its acoustic parameter data (pitch, sound length, sound intensity).
[0024] Index library: For all syllables, the serial numbers of all samples in the large-scale recording sound library are recorded, and the relevant data of this syllable can be quickly obtained by searching the large-scale recording sound library from this serial number.
[0025] Prosodic model library: The prosody model obtained through statistical training, that is, what the pitch, sound length, and sound intensity of each syllable in a sentence should be like. The values of these acoustic parameters are closely related to factors such as sentence pattern, part-of-speech sequence, and length of sentences and prosodic phrases.
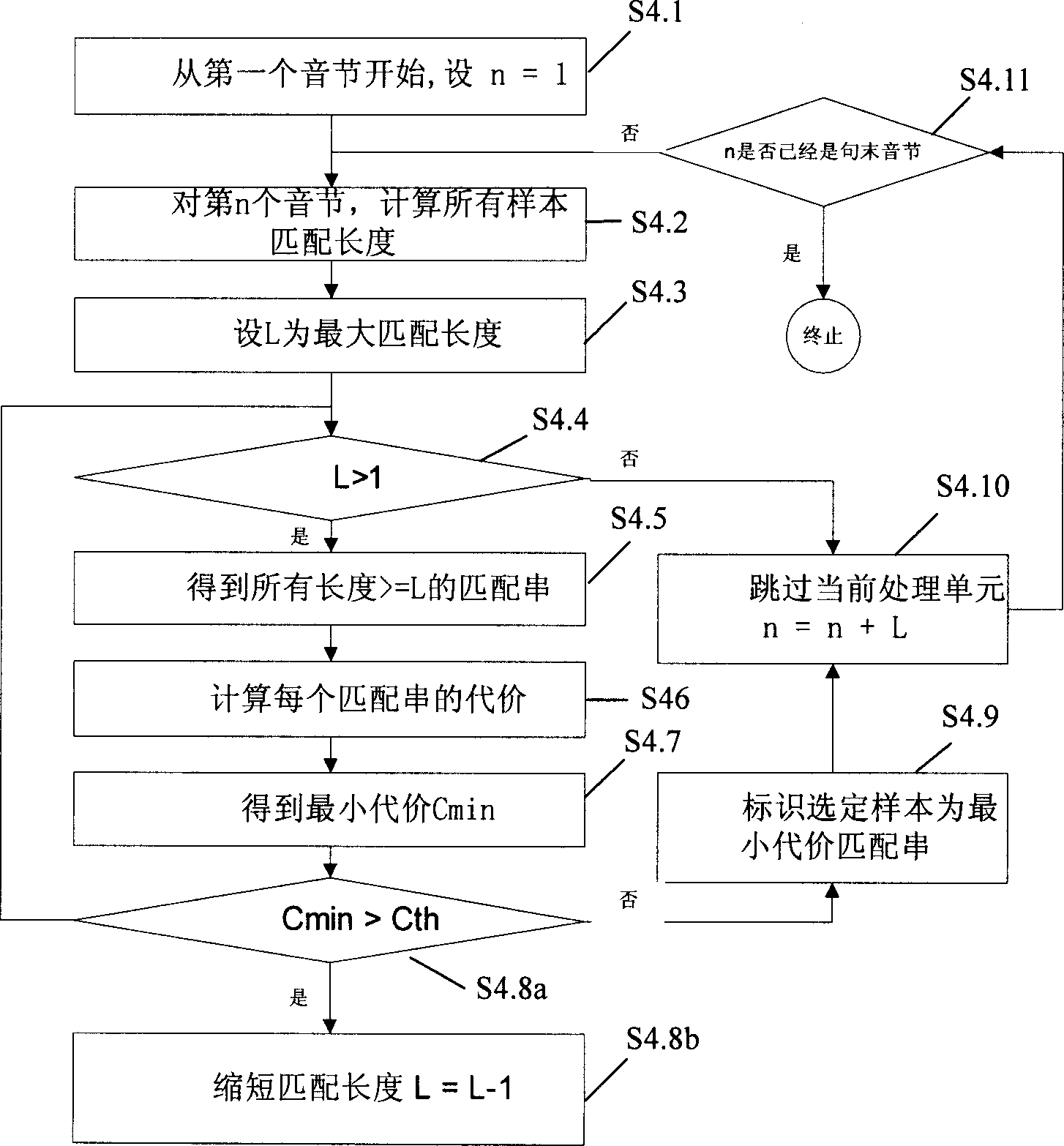
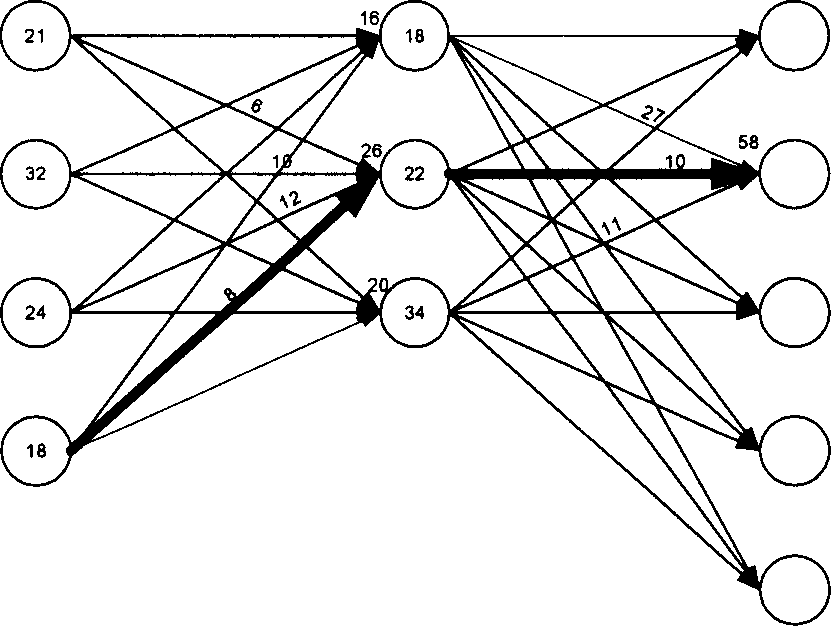
[0026] Such as figure 1 The process of speech synthesi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More