

Statement-level Chinese and English mixed input method
A mixed input, Chinese and English technology, applied in the input/output process of data processing, instruments, electronic digital data processing, etc., can solve the problem of unable to guarantee sentence input, etc., to reduce the burden of thinking, improve input efficiency, and improve input habits Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
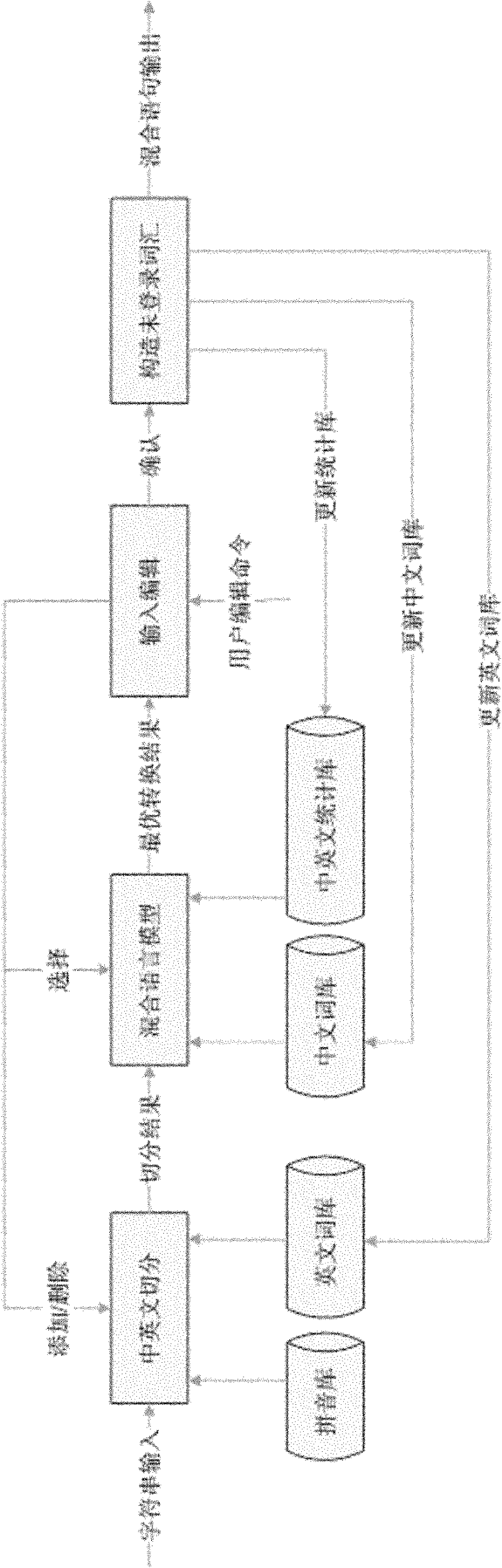
[0009] Specific implementation mode one: the following combination Figure 1 to Figure 3 This embodiment will be described. It includes the following steps: 1. Input character strings with a keyboard; 2. Segment the character strings in Chinese and English by the input method management system; the Chinese-English segmentation is based on the automatic recognition of the Chinese pinyin database and the English thesaurus; 3. The input method management system performs corresponding Chinese and English character conversions on the segmented strings, and provides mixed sentence candidates and Chinese and English word candidates; the Chinese and English character conversions made are based on the Chinese thesaurus and Chinese Automatic recognition of English statistical database; 4. Select output content from the candidate list including mixed sentence candidates and Chinese and English word candidates through editing commands such as insert, delete, and select; 5. Output Chinese ...
specific Embodiment approach 2
[0019] Specific embodiment two: the difference between this embodiment and embodiment one is: it also includes step 6, according to the Chinese-English mixed sentence that step 5 outputs, construct Chinese unregistered vocabulary and English unregistered vocabulary and to English thesaurus, Chinese Thesaurus and Chinese and English statistical databases are updated.
[0020]The existing Chinese unregistered word recognition methods mainly include two methods based on statistics and based on rules. Statistics-based methods generally use statistical strategies to extract candidate strings, and then use language knowledge to exclude garbage strings that are not new words, which are suitable for processing large-scale corpus and are not limited by domains. However, its recall rate is low, it is sensitive to the problem of data sparsity, and there is a danger of "short word priority". The rule-based method usually builds a rule base, a professional thesaurus or a pattern base base...
specific Embodiment approach 3
[0022] Specific Embodiment Three: An example is specifically given below to illustrate the method of the present invention. Such as figure 1 As shown, the sentence-level Chinese-English mixed input first needs to be segmented into Chinese and English to recognize Chinese pinyin syllables and English words. After Chinese and English segmentation, according to the recognition result, the input method management system of the present invention performs corresponding Chinese and English character conversion on the segmented character strings, and provides mixed sentence candidates and Chinese and English word candidates. The user performs editing operations according to the Chinese and English segmentation results and candidates, and finally confirms the output. The present invention has fully considered Quanpin and Jianpin when Chinese syllables are segmented, and for the sake of convenience, Quanpin is mainly used in the process of illustration.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More