

Method which is used for classifying translation manuscript in automatic fragmentation mode and based on large-scale term corpus
A corpus and large-scale technology, applied in special data processing applications, instruments, electronic digital data processing, etc., can solve problems such as unfavorable translation fragmentation classification methods, improve classification efficiency, shorten classification time, and reduce query time Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
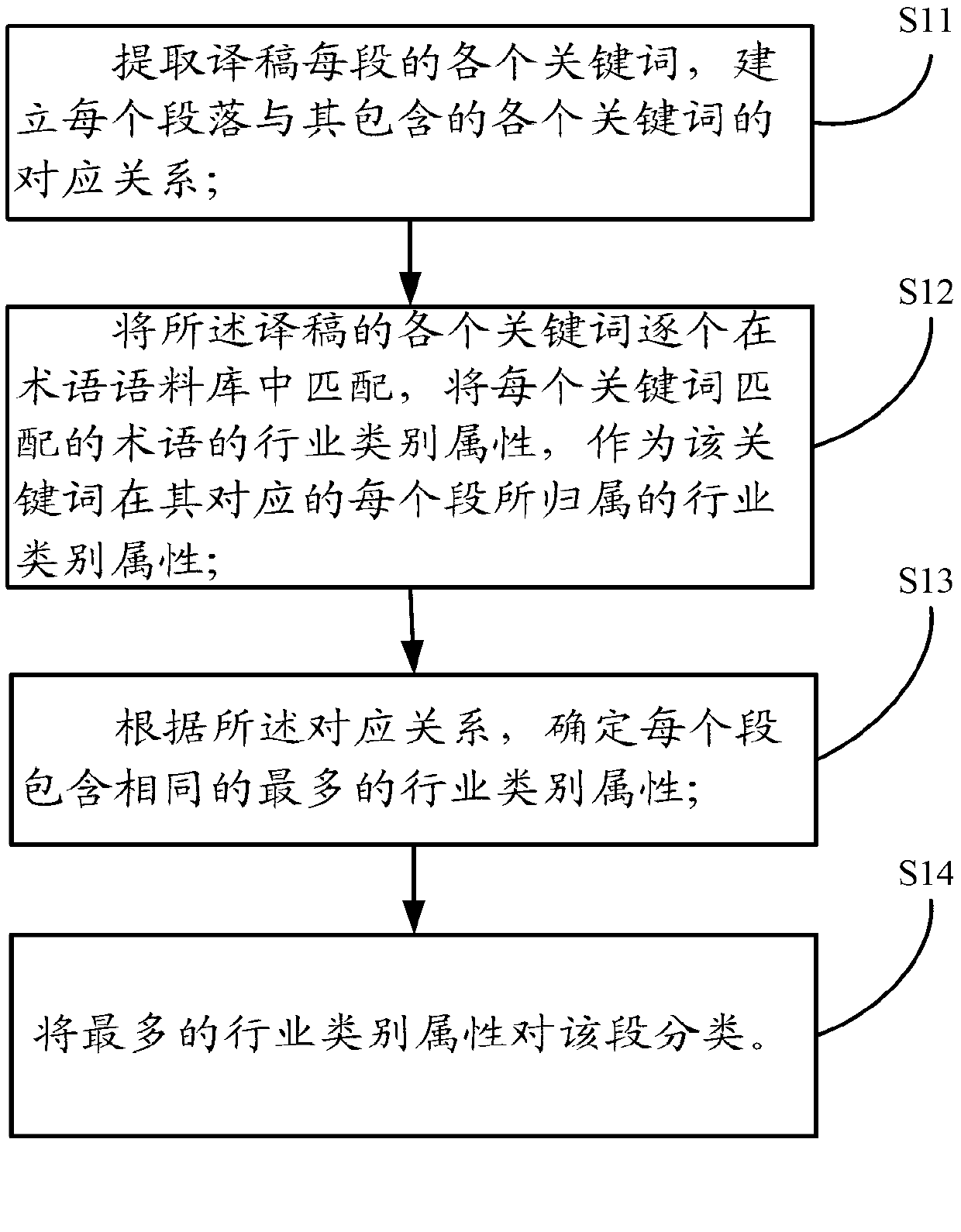
[0027] The present invention will be described in detail below with reference to the accompanying drawings and in combination with embodiments. see figure 1 , the process of the embodiment includes:
[0028] S11: Extract each keyword of each paragraph of the translated manuscript, and establish a corresponding relationship between each paragraph and each keyword contained therein;
[0029] S12: Match each keyword of the translated manuscript in the term corpus one by one, and use the industry category attribute of the term matched by each keyword as the industry category attribute to which the keyword belongs in each segment corresponding to it;
[0030] S13: According to the corresponding relationship, determine that each segment contains the same maximum industry category attributes;
[0031] S14: classify the segment with the most industry category attributes.
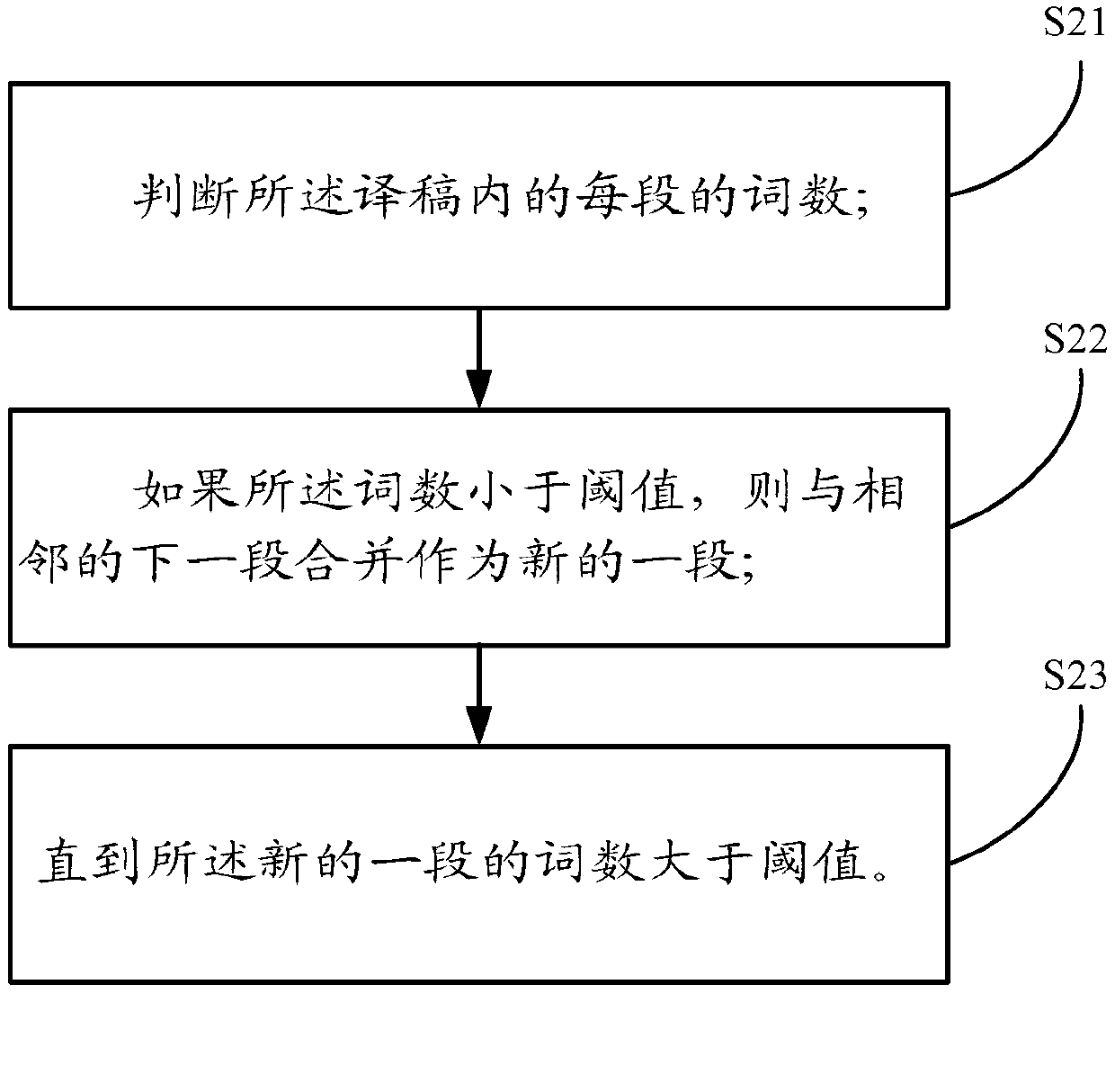
[0032] Since the number of words in the document to be translated is much smaller than the number of words in ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More