

A distributed topic discovery method and system for big data
A discovery method and distributed technology, applied in news media industry, Web big data analysis, Internet industry, can solve problems such as inability to process massive data, imperfect keyword scoring mechanism, etc., to reduce memory pressure and computing pressure.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
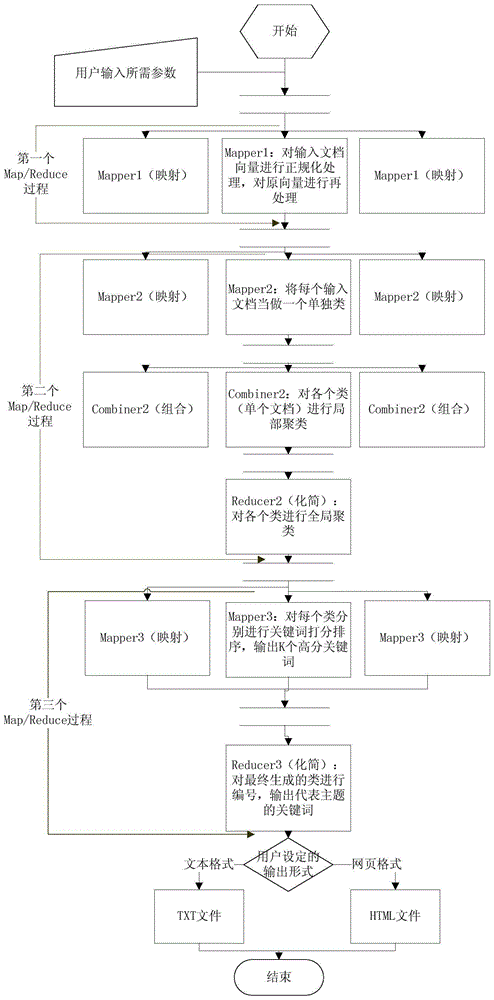
[0048] The present invention is based on the open-source software platform Hadoop, utilizes Map / Reduce (mapping / simplification) programming frame (this programming frame is used for the parallel computing of large-scale TB level data set, adopts the thought of " divide and conquer " on it, the large-scale The operation of the data set is distributed to the sub-nodes under the management of a master node to complete together, and then the final result is obtained by integrating the intermediate results of each sub-node.) It improves the traditional single-path clustering topic discovery process to achieve distributed calculation purposes.
[0049] The technical solution is generally divided into three Map / Reduce processes.
[0050] The initial input is a text file stored on HDFS (distributed file system) containing all documents to be processed, and the format of each line is: "webpage name $ webpage title name\t word number in the dictionary: word frequency".
[0051] The big...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More