

Text similarity computing method
A text similarity and calculation method technology, applied in the field of personalized product recommendation, can solve problems such as not applicable to ordinary e-commerce models
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

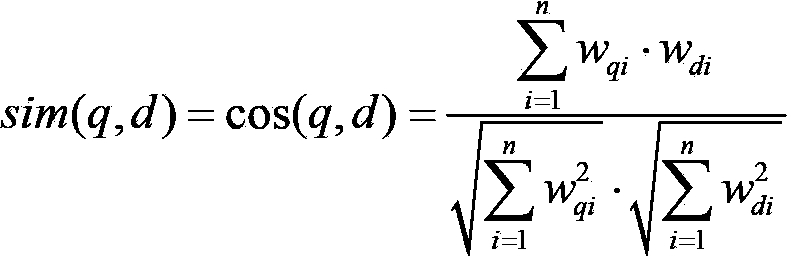
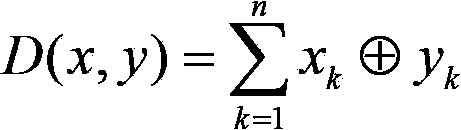
Examples
Embodiment Construction
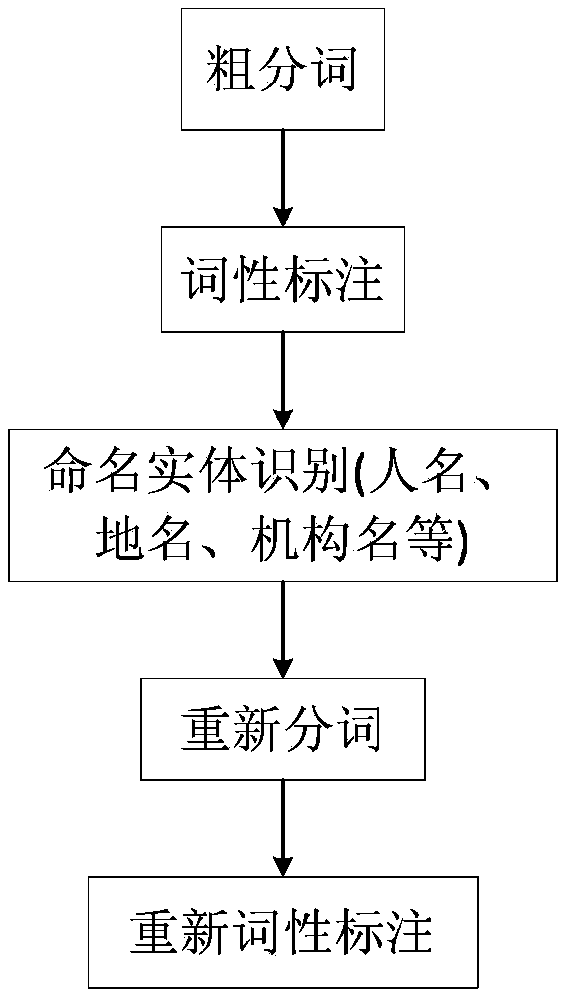
[0029] Such as figure 1 Calculation of the similarity of the text shown: After the feature vector is determined, all texts must be standardized using the final feature set after word segmentation, and all texts can be described by a vector. The traditional text similarity calculation method is to use the vector space model, according to the word frequency TF and the inverse text frequency IDF, to give the weight of each component of the vector, which corresponds to the vector in the Euclidean space one by one, and borrow the cosine of the vector angle in the Euclidean space The method to obtain a quantitative representation of the similarity between text q and d is shown in the following three formulas:
[0030] q={w q1 ,w q2 ,...,w qn}
[0031] d={w d1 ,w d2 ,...,w dn}
[0032] sim ( q , d ) = cos ( q , d ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More